Le storie della settimana
Questa settimana:
Regole di Internet:
• L’ipotesi di vendita di PagoPA a Poste Italiane • Stati Uniti vs TikTok
Intelligenze artificiali:
• Il punto di svolta per i robot umanoidi • xAI pubblica Grok • Le grandi manovre di Apple per riuscire a sorprendere • La nuova GPU di NVIDIA • C’era una volta un paper • Grandi manovre negli USA • Vero o falso? • 500 italiani e italiane che contano nell’intelligenza artificiale • La Rai farà “opt out” dall’AI
Reti e TLC:
• L’AGCOM mischia le carte su Piracy Shield • Cloudflare invita a reclamare contro AGCOM • La Corte dei Conti certifica i ritardi del piano BUL • Anche Azure permetterà l’esportazione gratuita dei dati • La vita dopo Twitch, in Corea del Sud
In real life:
• Le elezioni in Russia, con la statistica
Cybersecurity:
• L’architettura del nuovo “Safe Browsing” di Google Chrome • La vulnerabilità di M1 e M2 di Apple che permette di estrarre chiavi crittografiche • Una vulnerabilità DoS in QUIC • Apple ha rotto Java su macOS
Regole di Internet
• L’ipotesi di vendita di PagoPA a Poste Italiane
Il governo sta iniziando a mettere in pratica il piano di privatizzazioni che ha l’obiettivo di recuperare circa 20 miliardi di euro in tre anni. Fa parte di questo piano anche la vendita di PagoPA SpA, la società che gestisce il sistema per i pagamenti verso la pubblica amministrazione.
La società è attualmente di proprietà del Ministero dell’Economia ma il piano prevede di cedere fino al 51% delle quote all’Istituto Poligrafico e Zecca dello Stato mentre la restate quota andrebbe a Poste Italiane. Anche Poste è però coinvolta in questo piano di privatizzazioni e ci sarebbe quindi il rischio che l’infrastruttura per i pagamenti pubblici finisca sotto il controllo di soggetti privati.
Qualche giorno fa l’Antitrust ha fatto presente che una presenza rilevante di Poste in PagoPA produrrebbe anche un forte conflitto di interessi perché Poste è uno degli intermediari di pagamento accreditati sulla piattaforma PagoPA. In passato l’Antitrust aveva tra l’altro dato un parere negativo all’ipotesi di rendere PagoPA il sistema unico dei pagamenti, evidenziando i rischi di concentrare tutti i pagamenti in un’unica piattaforma, che come stiamo in effetti vedendo in questi giorni non è nemmeno garantito che si riesca a mantenere imparziale e sotto il controllo pubblico.


• Stati Uniti vs TikTok
Si è molto discusso nelle ultime settimane della nuova legge approvata dalla Camera degli Stati Uniti che potrebbe costringere l’azienda che possiede TikTok, la cinese ByteDance, a vendere l’applicazione entro 6 mesi. La legge non è ancora stata approvata definitivamente: deve passare prima dal Senato e potrebbe non essere nemmeno discussa.
Ci sarebbero comunque un’infinità di riflessioni da fare e servirebbe una newsletter intera solo per questo (rimando al primo link nelle fonti per chi vuole approfondire). Non va però perso di vista il fatto che la questione è più politica che tecnica: il fatto che l’app raccolga o meno determinati dati non è rilevante di fronte a una realtà in cui le aziende cinesi private di fatto hanno ben poco di privato perché fanno parte del sistema di sorveglianza del governo. Non stiamo tra l’altro aspettando che succeda qualcosa di scandaloso per averne conferma: è già successo. TikTok ha già ammesso in passato che ha sfruttato l’app per spiare i movimenti di alcuni giornalisti.
La legge in discussione negli Stati Uniti potrebbe sembrare drastica (anche se l’India, un mercato enorme, ha già bloccato l’app nel 2020, senza catastrofi), ma l’impressione è che ci siano ben pochi argomenti che tengano per difendere TikTok. L’eventuale vendita comunque favorirebbe probabilmente le aziende statunitensi, già presenti come principali investitori in ByteDance.


Intelligenze artificiali
• Il punto di svolta per i robot umanoidi
Ci sono diverse aziende e startup che stanno lavorando a robot dalle sembianze umane che possano agire e interagire con comportamenti umani. Finora questi comportamenti sono stati difficilmente replicabili da dei robot, ma qualche giorno fa ha stupito molto una nuova demo di Figure, una startup statunitense, in cui un robot mostra capacità di ragionamento “speech-to-speech”. È cioè in grado di interpretare le richieste espresse con la voce e il linguaggio naturale e agire in risposta in modo molto naturale, come farebbe un umano.
Non è molto chiaro quanto di questa demo sia reale o programmato, ma è comunque un risultato sorprendente che forse possiamo considerare un’anteprima del futuro. Figure dichiara che i suoi robot potranno essere usati per l’assistenza domestica, per svolgere lavori umani o per l’esplorazione dello spazio, ma manca probabilmente ancora molto per raggiungere una maturità sufficiente da poter produrre e vendere i robot sul mercato.


• xAI pubblica Grok
Domenica scorsa xAI ha annunciato il primo rilascio pubblico di Grok, il modello linguistico di grandi dimensioni sviluppato nel corso dell’ultimo anno. L’azienda xAI è stata fondata l’anno scorso da Elon Musk per competere con OpenAI sui modelli di AI generativa e ha annunciato e messo a disposizione una prima versione del modello in tempi straordinariamente veloci.

Ora i pesi della rete neurale del modello sono stati resi pubblici tramite un torrent da 318 GB: è infatti un modello da 314 miliardi di parametri, il più grande modello linguistico mai rilasciato pubblicamente. Per eseguirlo servono GPU o cluster di GPU con centinaia di gigabyte di memoria e quindi per ora in pochi sono stati in grado di eseguirlo.
Si tratta poi di un modello “base” senza nessun fine-tuning specifico e non è quindi adatto “out of the box” per realizzare ad esempio chat per conversare con il modello. L’architettura è Mixture of Experts (MoE), come per GPT-4 e tutti i modelli di punta, e cioè la rete neurale è composta da più “esperti” più piccoli (in questo caso 8) e per generare ciascun token viene attivato solo il 25% della rete, in modo dinamico. Il vocabolario è composto da 131mila token, una quantità simile a GPT-4.



• Le grandi manovre di Apple per riuscire a sorprendere
In questo anno e mezzo di grandi evoluzioni spinte dall’AI generativa Apple è stata largamente in silenzio. L’azienda ha sempre fatto molta fatica anche solo ad usare il termine “AI”, preferendo un approccio più cauto. Questa volta però rischia di restare tagliata fuori da una rivoluzione con una forza rara, e sappiamo che da tempo ha aumentato gli investimenti in intelligenza artificiale.
Ci si aspetta che a giugno alla conferenza annuale per sviluppatori, la WWDC, Apple presenti la nuova versione di iOS che dovrebbe includere un nuovo Siri più intelligente e basato sui nuovi modelli linguistici specializzati per il dialogo. Quello che non è ancora chiaro è come lo farà: questa settimana ci sono stati due segnali contrastanti che non chiariscono a che punto si trovi Apple.
Prima Apple ha pubblicato un paper di ricerca in cui illustra un nuovo modello, chiamato MM1, di qualità discreta ma con risultati interessanti sui task visuali. In contemporanea sono uscite delle indiscrezioni di Bloomberg, quindi tendenzialmente affidabili, sul fatto che Apple si starebbe accordando con Google e forse anche con OpenAI per usare i modelli Gemini e GPT per le nuove funzionalità AI di iOS 18.
Una cosa è certa: Apple questa volta deve stupire o rischia di fare la figura di chi insegue e non riesce (più) a differenziarsi.



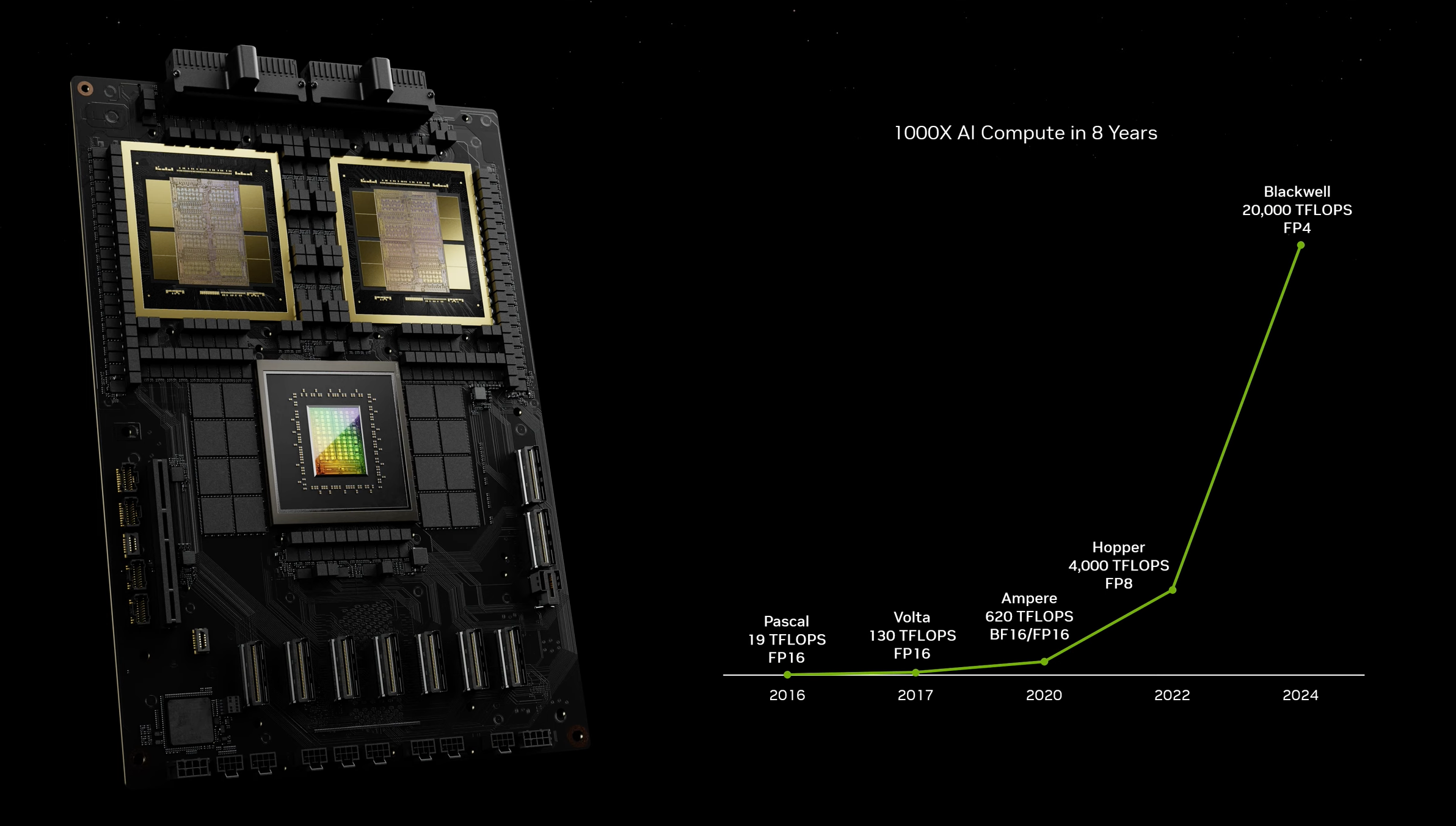
• La nuova GPU di NVIDIA
NVIDIA ha annunciato una nuova architettura per GPU, chiamata Blackwell, la GPU B200 e il “superchip” GB200 (cioè l’unione di due B200), con un focus particolare sulle applicazioni legate all’AI generativa. La peculiarità di questa nuova generazione di GPU è una capacità di calcolo molto superiore rispetto alla generazione precedente (5 volte la potenza computazionale di una H100) promettendo così una riduzione significativa del consumo energetico a parità di task.
Ad esempio, l’azienda stima che per completare il training di un modello da 1.800 miliardi di parametri, come GPT-4, sono richieste “solo” 2.000 GPU Blackwell per 90 giorni, rispetto alle 8.000 necessarie in precedenza.

• C’era una volta un paper
La “rivoluzione” nell’intelligenza artificiale dell’ultimo anno e mezzo ha origine in larga parte da un celebre paper del 2017 pubblicato da alcuni ricercatori di Google. Il paper si intitola Attention Is All You Need e presenta una architettura chiamata “transformer” oggi usata da tutti i modelli linguistici, ChatGPT incluso. Una delle grandi innovazioni del paper stava nella proposta di usare il meccanismo dell’attenzione per permettere al processo di generazione di ciascun token di tenere in considerazione il resto del testo con livelli di attenzione diversi per le varie parti, in modo non distante da come fanno gli umani.
«When the transformer paper came out, I don’t think anyone at Google realized what it meant»
Un articolo di Wired ha raccontato la storia degli 8 autori del paper, 6 dei quali nati fuori dagli Stati Uniti, che oggi sappiamo hanno fatto un pezzo di storia. Nessuno di loro lavora più per Google: in 7 hanno fondato nuove aziende che realizzano progetti basati sull’architettura transformer mentre l’ottavo è un ricercatore di OpenAI. Secondo uno degli autori, Google avrebbe potuto produrre un ChatGPT già nel 2019, tre anni prima di OpenAI, ma Google non è riuscita a cogliere l’opportunità. Anche se aveva tutto.
• Grandi manovre negli USA
Questa settimana c’è stato uno sviluppo importante nel panorama delle aziende statunitensi che si occupano di AI generativa.
Mustafa Suleyman, il fondatore di una delle startup più promettenti, Inflection AI, ha annunciato che lascerà la guida della startup per andare a dirigere in Microsoft una nuova divisione chiamata Microsoft AI, che supervisionerà tutta la ricerca in AI e la realizzazione di prodotti come Copilot, Bing e Edge, facendo capo direttamente al CEO Satya Nadella.
Suleyman ha lavorato in Google fino al 2022 ed è stato uno dei fondatori di DeepMind, importante laboratorio di ricerca fondato nel 2010 a Londra e poi inglobato in Google. Si porterà con sé anche la co-fondatrice di Inflection AI e diversi dipendenti della startup. Molti hanno visto questa operazione come un acquisto di fatto da parte di Microsoft, con il vantaggio che senza un’acquisizione formale si evita il rischio di incastrarsi in questioni di antitrust. TechCrunch ha scritto che «Inflection AI è stata mangiata viva», ma è senza dubbio un grande colpo per Microsoft che assume così uno dei principali esperti al mondo nel settore e aumenta significativamente le proprie competenze interne.
«After raising $1.3B, Inflection is eaten alive by its biggest investor, Microsoft»
Da un altro punto di vista questa non-acquisizione potrebbe anche essere una conseguenza della difficoltà di Inflection AI nel trovare un business model funzionante, persino dopo aver ricevuto investimenti per ben 1,3 miliardi di dollari. Il prodotto principale della startup, l’assistente Pi, non si è diffuso come sperato e mentre Inflection AI si concentrerà più sulle aziende si è anche parlato della possibilità che Pi venga dismesso. A provare questa difficoltà nel distinguersi ci sarebbe anche il fatto che secondo recenti indiscrezioni un’altra concorrente di OpenAI, Cohere, avrebbe un fatturato annuo di solo 13 milioni di dollari a fronte di una valutazione di 6 miliardi, 450 volte tanto.
Anche dentro Google intanto sono in corso riorganizzazioni, con la scelta di una nuova guida per la divisione Search. È un ulteriore segno che Google sta provando a spingere ulteriormente per convertire il motore di ricerca tradizionale nella direzione di uno strumento più intelligente che possa meglio competere nel futuro.
Dalle parti di Stability AI, che realizza i noti modelli di generazione immagini della serie Stable Diffusion, potrebbero invece esserci dei guai: tre ricercatori, gli autori originali di Stable Diffusion, hanno lasciato l’azienda e il CEO della startup, figura per molti controversa perché “catapultata” in un progetto in cui aveva pochi meriti, ha lasciato il ruolo. Stability è anche coinvolta in cause legali perché avrebbe usato materiale fotografico per il training in modo illegale.

• Vero o falso?
Guardate l’immagine in questo tweet. Riuscite a identificare quale parte dell’immagine è reale e quale è generata con AI? La soluzione è qua.
Riuscire a distinguere la realtà dalle immagini generate diventerà sempre più difficile. Questa settimana YouTube ha iniziato a mettere delle toppe annunciando una nuova impostazione che permette di dichiarare che un video caricato sulla piattaforma è almeno parzialmente manipolato.
• 500 italiani e italiane che contano nell’intelligenza artificiale
La Repubblica ha fatto un enorme lavoro di raccolta delle biografie di circa 500 persone italiane che svolgono ricerca o lavorano nel campo dell’intelligenza artificiale.
“Quel che serve per l’AI” è invece una riflessione di Alfonso Fuggetta, esperto di innovazione digitale, sulla necessità di smettere di parlare di “obiettivi strategici” o di “tecnologia centrale” senza avere un’idea di cosa si stia parlando e cosa sia necessario per competere.


• La Rai farà “opt out” dall’AI
La Rai ha deciso che impedirà l’uso dei propri contenuti per il training di AI generativa. Il consiglio di amministrazione ha deciso che «la Rai eserciterà la facoltà cosiddetta di opt out: proteggerà dunque i propri contenuti, da un lato attraverso l’utilizzo di tecnologie specifiche e dall’altro segnalando esplicitamente con un disclaimer la volontà di Rai - in quanto titolare dei contenuti - di vietarne la riproduzione o l’utilizzo alle Piattaforme di Intelligenza artificiale in linea con i principali servizi pubblici europei».
Reti e TLC
• L’AGCOM mischia le carte su Piracy Shield
Mercoledì scorso alcuni rappresentanti di AGCOM, l’autorità garante per le comunicazioni, sono stati convocati in audizione alla IX Commissione (trasporti e telecomunicazioni) della Camera dei Deputati per un aggiornamento sulla piattaforma Piracy Shield. Il sistema, in funzione da inizio febbraio, ha lo scopo di bloccare in modo quasi istantaneo i siti web che trasmettono contenuti sportivi, prevalentemente calcio, sia tramite blocco del dominio (con il DNS) che tramite indirizzo IP.
Tra mille controversie, i dubbi sollevati dagli esperti nel corso degli ultimi mesi si sono tutti avverati: la trasparenza inesistente e le CDN bloccate per errore hanno portato a questa audizione dove il presidente di AGCOM, Giacomo Lasorella, ha provato a spiegare la situazione.
Ha detto che sono stati accreditati 5 soggetti segnalatori, cioè DAZN, Lega Serie A, Lega Serie B, Mediaset e Sky, che in questo mese e mezzo hanno richiesto il blocco di 3127 domini e 2166 indirizzi IP. Si è trattato in larga parte di streaming di calcio ma durante l’audizione è stata citata anche la Formula 1, la MotoGP, il tennis e la pallacanestro.
Il presidente Lasorella se l’è poi presa con chi in queste settimane ha evidenziato pubblicamente quando si stavano facendo degli errori bloccando indirizzi IP ospitanti siti leciti: «a noi non sono arrivati reclami, quindi questo fenomeno che è stato anche enfatizzato da taluni sul web in fondo non ha avuto una ricaduta in termini di specifici reclami. Non sono stati buttati giù siti che ospitavano anche altre cose. C’è stato un unico caso che è rientrato abbastanza rapidamente».
E di nuovo: «Sugli indirizzi IP “non univoci”, […] su tremila blocchi non è mai stato fatto. Finora abbiamo buttato giù soltanto i siti univocamente dedicati a questo. L’unico caso in cui la questione è stata minimamente controversa la segnalazione è stata ritirata immediatamente e quindi c’è stato un ripristino in una mezz’oretta. E poi non abbiamo avuto reclami. So che se n’è parlato molto sul web però c’è uno strumento che è il reclamo se uno avesse avuto qualcosa di cui dolersi formalmente avrebbe potuto tranquillamente indirizzare un reclamo».
«A noi non sono arrivati reclami»
Queste affermazioni sono false: è stato dimostrato da diversi esperti del settore che AGCOM ha bloccato non solo un indirizzo IP del servizio cloud Zenlayer, ma anche un IP della CDN Cloudflare, causando problemi a decine di migliaia di siti web. Non è nemmeno vero che «c’è stato un ripristino in una mezz’oretta»: non ci è dato sapere con precisione dopo quanto tempo il ticket di blocco sia stato revocato, ma di fatto l’indirizzo IP è rimasto bloccato fino a 40 ore in alcuni casi.
È evidentemente falso anche che AGCOM non abbia ricevuto reclami. Ci sono testimonianze di reclami formali inviati ad AGCOM già il giorno dopo il blocco. Se nemmeno una PEC si può considerare reclamo, cos’è un reclamo?
Il presidente Lasorella ha fatto poi notare che in caso di blocco «compare una schermata che rinvia all’autorità e quindi dà notizia del blocco». L’AGCOM, che si occupa di telecomunicazioni per mestiere, dovrebbe però ben sapere che per motivi tecnici ovvi a tutti nel settore è molto difficile mostrare questa schermata in modo affidabile. È così che funziona Internet: non si può impersonare facilmente e in modo affidabile un sito web.

Anche se la schermata fosse stata mostrata, comunque, il messaggio non avrebbe indicato come si può fare reclamo e sarebbe stata responsabilità della vittima districarsi tra le delibere AGCOM per capire come funziona il sistema. Negli uffici di AGCOM dove la burocrazia è lo standard forse questo è ritenuto sufficiente, ma nel mondo reale non lo è.
Restano comunque irrisolti i dubbi principali. Nel settore la regola è che dopo un problema di queste dimensioni si scriva un rapporto “post-mortem”, pubblico nei casi di maggiore impatto, che analizzi cosa è successo, che impatto ha avuto, cosa è stato fatto per rimediare e cosa si prevede di fare per evitare che avvenga di nuovo. Con Piracy Shield al momento siamo bloccati da settimane a “non è successo niente e se è successo siamo stati bravi, fidatevi”.
Per finire, durante l’audizione il rappresentante di AGCOM se l’è presa più volte con Cloudflare e Google. In particolare, sostiene Lasorella, Cloudflare «nell’offrire servizi quali OpenDNS e VPN di fatto agevola le attività in violazione del diritto d’autore online». In realtà il servizio OpenDNS è di Cisco, non di Cloudflare. Per quanto riguarda Google Public DNS (8.8.8.8), invece, «oggi gli “open DNS” costituiscono uno strumento attraverso cui l’utente può aggirare blocchi della circolazione su internet. […] Obiettivamente questo sistema lascia lo spazio aperto - non voglio dire favorisce - per queste attività illecite perché di fatto consente di aggirare i blocchi che sono posti dagli ISP».
Oppure, si potrebbe persino azzardare, c’è un motivo se l’infrastruttura di Internet si limita a fare l’infrastruttura di Internet.

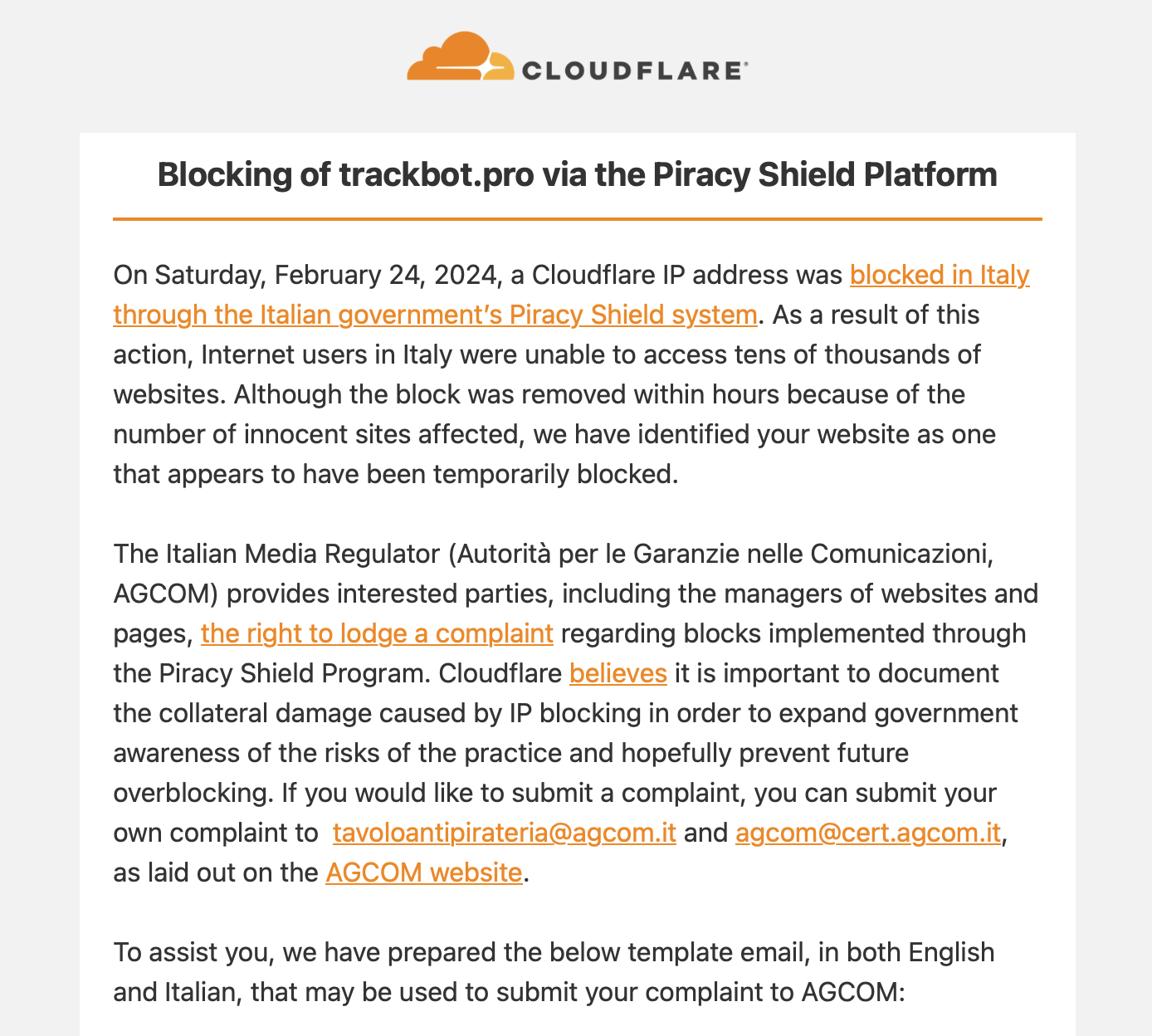
• Cloudflare invita a reclamare contro AGCOM
Poche ore dopo l’audizione di AGCOM alla Camera, Cloudflare ha inviato un’email a molti suoi clienti per avvisarli del blocco effettuato per errore tramite Piracy Shield. Secondo il testo dell’email il blocco avrebbe coinvolto «decine di migliaia» di siti web. Si dice che si tratti prevalentemente di siti sul piano gratuito di Cloudflare, che offre una soluzione CDN e di accelerazione dei siti web senza costi per la banda.
L’azienda ha invitato tutti i clienti potenzialmente impattati a inviare un reclamo tramite email o PEC direttamente ad AGCOM, fornendo anche un messaggio di esempio sia inglese che in italiano. Ora AGCOM non può più dire di non aver ricevuto reclami.
• La Corte dei Conti certifica i ritardi del piano BUL
La Corte dei Conti, l’organo dello Stato con funzione di controllo sulle spese e sul bilancio dello Stato, ha analizzato lo stato di avanzamento del piano banda ultralarga deliberando delle raccomandazioni per il governo in un documento di 33 pagine.
Il piano BUL, o più precisamente il piano aree bianche, è un progetto nato nel 2015 durante il governo Renzi con l’obiettivo di coprire con connettività a banda ultralarga, cioè al tempo ad almeno 30 Mbps, tutte le aree del paese che ne erano sprovviste, le aree bianche appunto. A distanza di 9 anni, il piano, la cui realizzazione è stata appaltata interamente a Open Fiber, non è ancora stato completato.
La realizzazione della copertura doveva completarsi entro il 2020 ma ha accumulato moltissimi ritardi. Le cause sono molte e comprendono ad esempio l’aver sottovalutato ampiamente la portata del piano (la copertura è quasi interamente da realizzare in FTTH, quindi spesso con molti scavi per portare la fibra ottica ad ogni abitazione), la scarsa preparazione di Open Fiber specialmente nelle prime fasi (l’azienda è nata proprio nel 2015) e la forte carenza di manodopera per la posa della fibra ottica, un problema mai risolto e ora ulteriormente aggravato dai nuovi progetti del PNRR. Un’ulteriore complicazione è stata l’aumento dei costi per le materie prime, e per questo il governo ha appena approvato un aumento dei fondi di 600 milioni di euro rispetto ai circa 3 miliardi originali.
Dal punto di vista di chi, come noi, osserva, la situazione è aggravata da una mancanza di trasparenza che ha caratterizzato l’intero piano: paradossalmente tutt’ora è spesso difficile ottenere dettagli precisi su quali abitazioni dovrebbero essere coinvolte (solo grazie alla delibera appena pubblicata si è finalmente riusciti ad ottenere almeno alcuni numeri, finora mai pubblicati, sugli obiettivi finali) e a distanza di quasi un decennio dall’avvio del progetto ci sono ancora comuni in cui la rete non è stata nemmeno progettata.
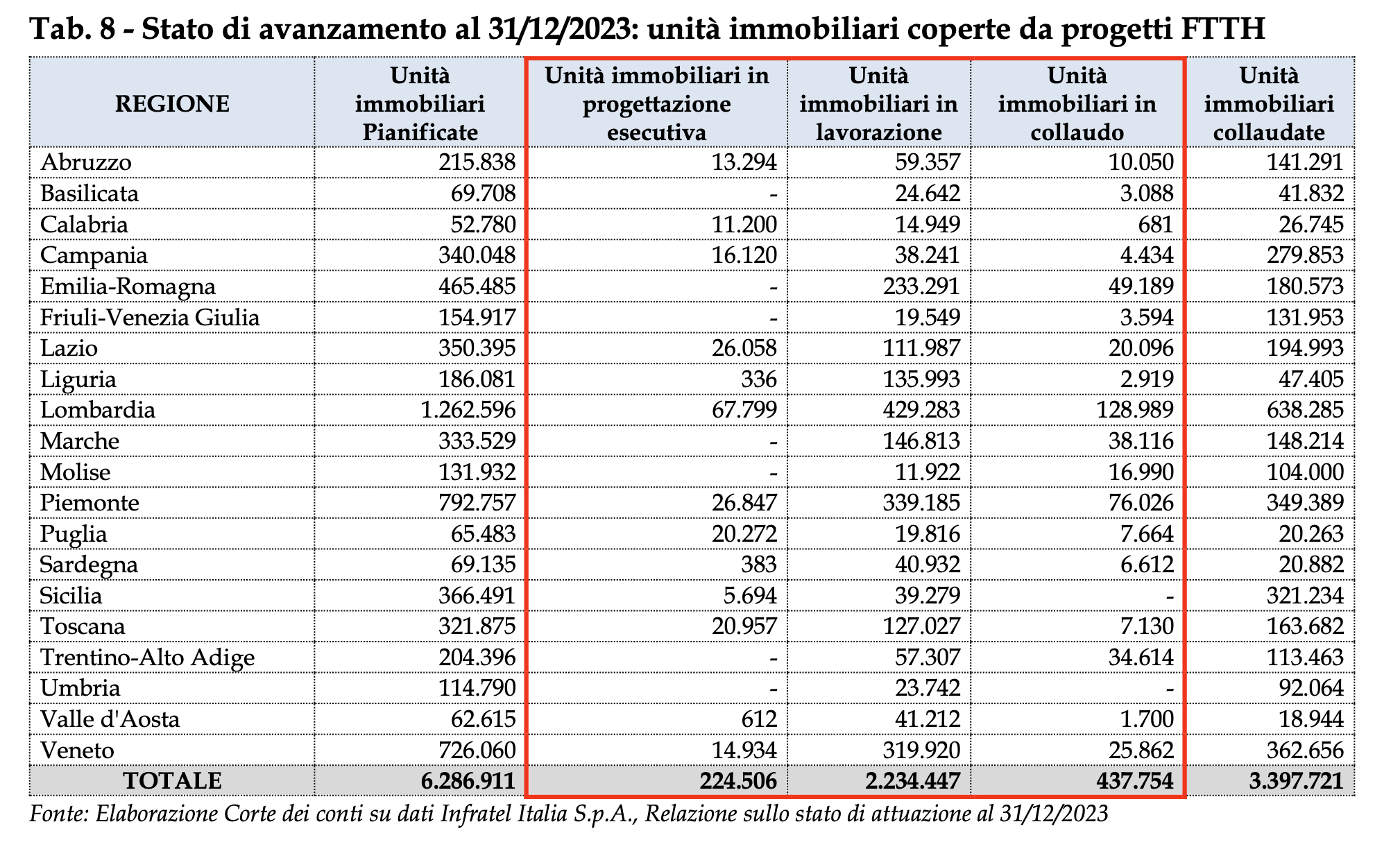
Il più recente cronoprogramma di Open Fiber, l’ultimo di una serie di cronoprogrammi sistematicamente smentiti dai fatti, prevede il completamento di tutte le opere entro settembre 2024. La Corte dei Conti osserva però che le abitazioni coperte in FTTH (e collaudate) a fine 2023 erano 3,4 milioni su un obiettivo di 6,3 milioni, solo il 54%. A queste vanno aggiunte altre 473mila (7%) in corso di collaudo e 2,2 milioni (36%) in lavorazione. Sommando tutti questi numeri si arriva a circa 6,1 milioni di abitazioni già coperte o in corso di copertura, il 97%.
Secondo i dati di Open Fiber, invece, le abitazioni coperte e “vendibili”, cioè attivabili ma non necessariamente collaudate, sono 4,54 milioni (72%). Dal punto di vista della rendicontazione dei fondi va però considerato il dato sui comuni collaudati.
Insomma, in base a quanto si vuole essere ottimisti e a quali dati si guardano si può dire che si inizia vedere la luce in fondo al tunnel. Ma la sfida ora è capire quanto tempo sarà necessario per completare la copertura rimanente facendo anche attenzione alle scadenze dei fondi che finanziano il progetto.

• Anche Azure permetterà l’esportazione gratuita dei dati
Dopo Google Cloud e Amazon Web Services, anche la piattaforma cloud Microsoft Azure consentirà ai clienti di migrare verso altri cloud senza incorrere in costi di banda in uscita per il trasferimento dei dati.
Questa non è stata una scelta autonoma di Azure. Come anche per Google e per Amazon si tratta di un obbligo previsto dall’Europan Data Act, regolamento europeo che impone alcune regole sull‘“economia dei dati”.

• La vita dopo Twitch, in Corea del Sud
In Corea del Sud sta procedendo il piano di Twitch per chiudere il servizio nel paese. Il motivo ha origine in una legge che secondo il principio “sender pays” obbliga i fornitori di contenuti come Twitch a pagare gli Internet Service Provider in base al traffico che generano sulle reti del paese per offrire i contenuti agli utenti finali.
Twitch ha comunicato a dicembre che i costi erano diventati insostenibili e che nonostante gli sforzi erano 10 volte più alti rispetto ad altri paesi in cui Twitch è presente. Per questo motivo l’azienda ha deciso di chiudere il servizio e dal 27 febbraio ha disattivato la monetizzazione per gli streamer coreani. Non è ancora chiaro se Twitch intende bloccare il servizio interamente in Corea del Sud, visto che al momento resta accessibile, ma sicuramente l’utilizzo si ridimensionerà significativamente dato che i creator sudcoreani non potranno più svolgere attività su Twitch come professione.

In real life
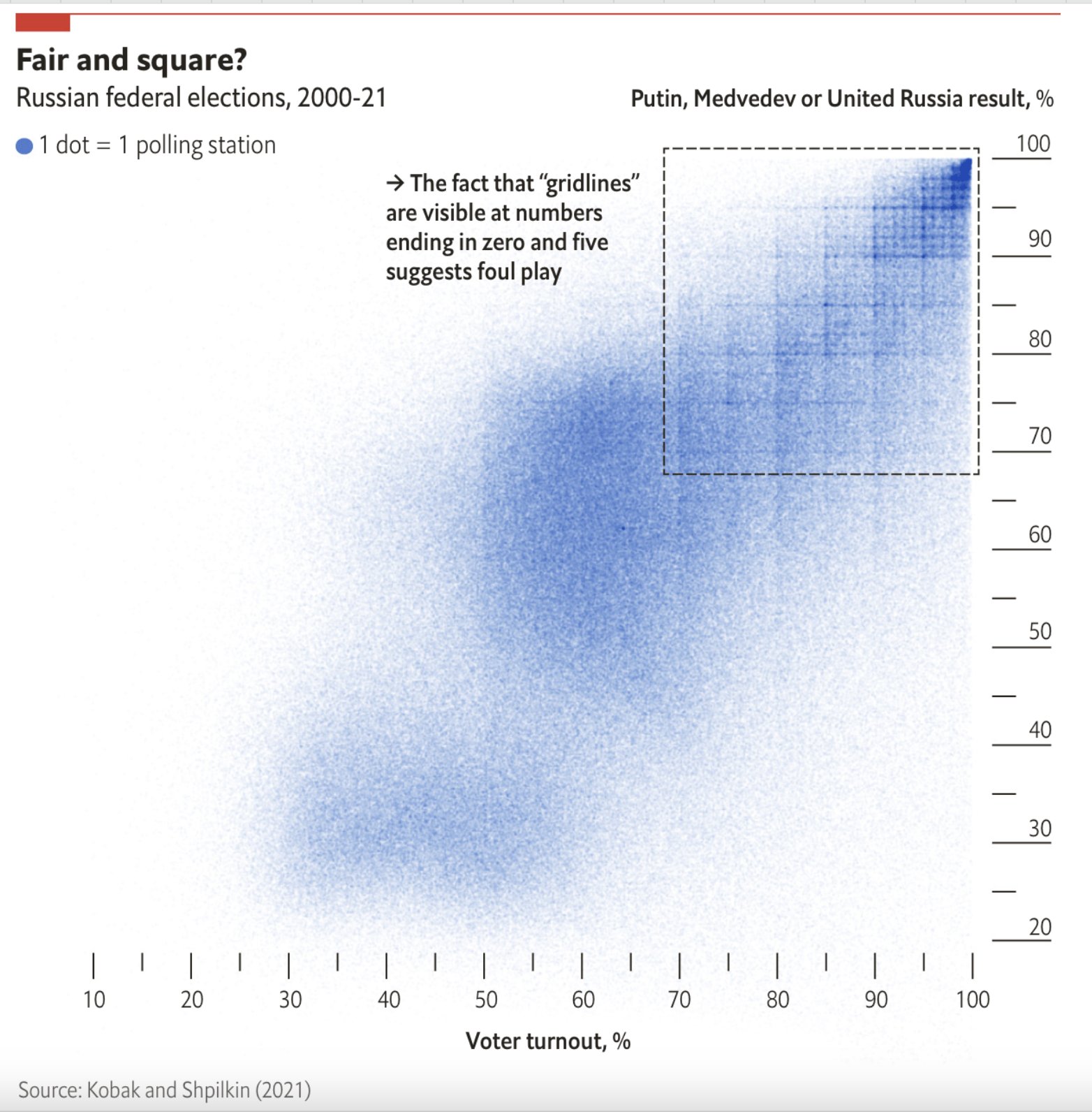
• Le elezioni in Russia, con la statistica
Da qualche anno c’è un lavoro di ricerca che prova ad individuare le anomalie nelle elezioni in Russia usando i dati ufficiali pubblicati dalle autorità russe. Si è scoperto che mettendo a confronto in modo visuale i dati sull’affluenza nei singoli seggi con la percentuale di voto per Putin si viene a creare una specie di griglia dove si vede che c’è un maggiore concentrazione di seggi dove sia l’affluenza che la percentuale sono numeri “tondi” come 80, 85, 90.
Questo metodo sfrutta la tendenza umana ad arrotondare i numeri e viene usato da anni per farsi un’idea del livello di falsificazione dei risultati delle elezioni. Anche nelle elezioni russe di quest’anno è stato notato lo stesso schema.
Cybersecurity
• L’architettura del nuovo “Safe Browsing” di Google Chrome
Google ha spiegato in un suo blog come è riuscita ad evolvere la funzione Safe Browsing di Google Chrome in modo che riesca a controllare se un URL è malevolo in tempo reale, pur preservando la privacy. Fino ad ora il sistema nelle sue impostazioni predefinite utilizzava una lista di hash di URL malevoli che veniva sincronizzata ogni 30-60 minuti. Secondo Google però “la maggior parte dei siti non sicuri esiste per meno di 10 minuti”. Si intende, presumo, che le pagine di phishing e simili sono molto dinamiche e quindi l’URL può cambiare continuamente.
Per risolvere questo problema Google ha ideato una complessa architettura che per preservare la privacy dei dati di navigazione disaccoppia il server Safe Browsing, cioè il server che contiene la lista sempre aggiornata di URL malevoli, e il server che riceve effettivamente le richieste HTTP da parte di Google Chrome per verificare se un URL specifico è da bloccare.
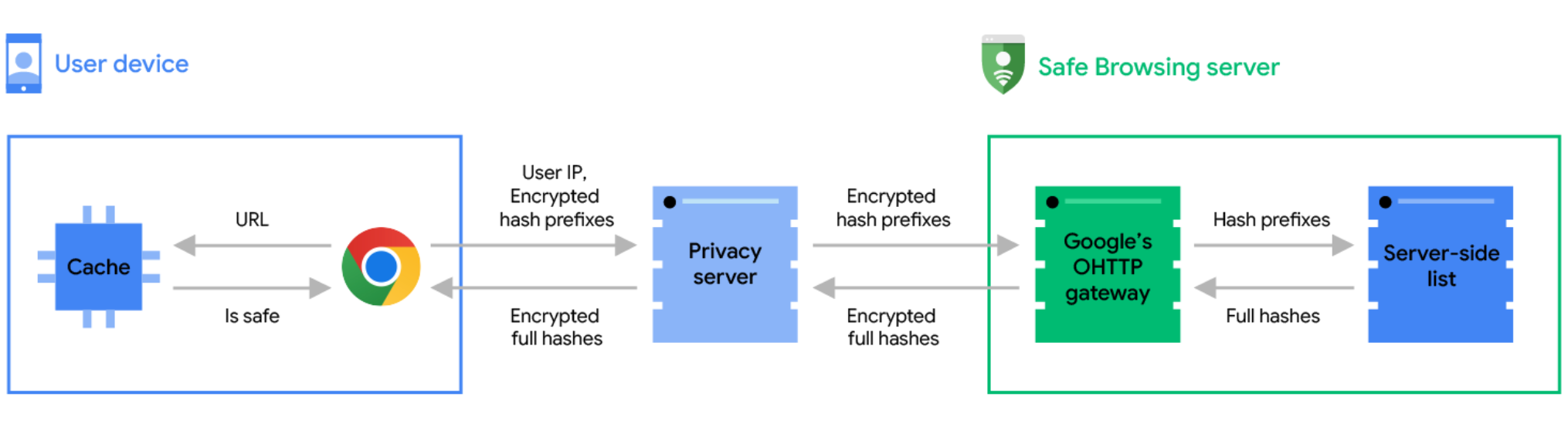
Il browser inizia calcolando un hash dell’URL da verificare, lo tronca ai primi 4 byte e lo trasmette a un server di privacy gestito dalla CDN Fastly, esterna a Google e indipendente, che implementa “Oblivious HTTP”. Il server Fastly inoltra poi le richieste al server Safe Browsing di Google ma l’uso di questo nuovo standard permette a Google di non sapere mai nemmeno l’indirizzo IP da cui la richiesta è partita. A quel punto il server Safe Browsing può fornire la risposta al client.
Esiste un ulteriore strato di protezione: l’hash dell’URL inviato al server è cifrato con crittografia a chiave pubblica e quindi solo il server Safe Browsing può leggere l’hash (troncato). In questo modo il server Fastly sa da chi arriva la richiesta ma non può vedere l’hash dell’URL, mentre il server Google sa qual è l’hash ma non può sapere da chi arriva la richiesta. È un sistema molto intelligente e ora è abilitato per tutti gli utenti Google Chrome per impostazione predefinita.
• La vulnerabilità di M1 e M2 di Apple che permette di estrarre chiavi crittografiche
Un gruppo di 7 ricercatori ha scoperto una vulnerabilità nel design dell’hardware dei chip M1 e M2 (ma non M3) di Apple che permette di estrarre le chiavi segrete da applicazioni che usano la crittografia.
La vulnerabilità è estremamente sofisticata ma è concettualmente simile a Spectre e Meltdown, due gravi vulnerabilità del 2018 che sfruttavano la funzione di esecuzione speculativa delle CPU per estrarre porzioni di memoria in modo non autorizzato. In quel caso le vulnerabilità avevano colpito principalmente le CPU Intel e i sistemi operativi avevano dovuto implementare delle patch software che avevano degradato le prestazioni dei sistemi anche in modo significativo.
In questo caso la parte del chip vulnerabile è un’ottimizzazione che prevede il caricamento di indirizzi di memoria nella cache della CPU in anticipo rispetto a quando la memoria è effettivamente richiesta (DMP), in modo da migliorare le prestazioni. Nel caso dei chip M1 e M2 questo meccanismo di prefetch è più evoluto perché non solo prova a predire il nuovo indirizzo di memoria da caricare in base a quale memoria è stata caricata nel passato, ma guarda anche il contenuto della memoria stessa per provare a rilevare se sono presenti dei (presunti) puntatori di memoria che probabilmente saranno utilizzati nel futuro.
Il problema nasce dal fatto che inducendo un’applicazione ad eseguire delle operazioni crittografiche con un determinato input è possibile spingere il sistema di prefetch ad attivarsi in condizioni specifiche. Il solo fatto che questo avviene permette a un attaccante di ricavare informazioni che a lungo andare (si parla di minuti) consentono di estrarre chiavi crittografiche segrete. Si parla quindi di un “side-channel attack”, un attacco che non sfrutta difetti nel funzionamento del sistema in sé ma si basa sul fatto che solo dall’osservazione di cosa succede in risposta a determinate operazioni si riescono ad ottenere informazioni utili per estrarre dati riservati.
Secondo i ricercatori non esiste una soluzione semplice perché il prefetcher non è disabilitabile, come invece avviene sui chip M3, ma ci sono punti di vista discordanti per cui è ancora presto per comprendere l’impatto della vulnerabilità.

• Una vulnerabilità DoS in QUIC
Uno sviluppatore che si occupa del protocollo QUIC ha scoperto una nuova vulnerabilità che permette di effettuare un attacco Denial of Service verso un server QUIC.
QUIC è il protocollo basato su UDP con l’ambizione di sostituire TCP, risolvendone vari limiti. Una novità di QUIC è che sullo stesso socket possono coesistere più connessioni QUIC, che sono identificate da un “connection ID”. La necessità di creare nuovi connection ID e ritirare quelli vecchi, anche per impedire di essere tracciati per tempi prolungati e magari su reti diverse, può essere però sfruttata per creare e ritirare continuamente connection ID, generando così sovraccarico sul server.
Le implementazioni dovrebbero quindi inserire un limite sulla quantità di connessioni che si possono ritirare, in modo da mitigare questo tipo di attacco.
• Apple ha rotto Java su macOS
Secondo un avviso pubblicato da Oracle, l’aggiornamento di macOS 14.4, uscito circa due settimane fa, rende Java inusabile per via di una modifica non documentata applicata da Apple all’ultimo momento, senza lasciare il tempo per testare. Non ci sono al momento soluzioni, per cui se vi serve Java è meglio se non aggiornate.
Appunti
- Come funzionano le reti 4G e 5G? Un video di Enrico Zoia su YouTube.
- Satoshi Nakamoto, creatore di Bitcoin di cui non si conosce l’identità, non è quell’uomo che da tempo sosteneva di esserlo. (Wired)
- Perché non si può parlare di “cyber-guerra”, talk di Stefano Zanero (Politecnico di Milano) su YouTube.
- Il registro dei domini .ai dice “non usate GoDaddy”. (DomainIncite)
</ in ~31 kB >