Le storie della settimana
Se arrivi dall’email di sabato 13 aprile, trovi la newsletter corretta a questo link. Il link nell’email era sbagliato.
Questa settimana:
Regole di Internet:
• Come si verifica l’età online? • Il governo USA fa causa a Apple, ma come finirà? • La Spagna ordina il blocco di Telegram, poi cambia idea
Reti e telecomunicazioni:
• Piracy Shield: un pasticcio dopo l’altro • OVH aprirà un datacenter in Italia • C’è fibra e fibra: l’italiana Prysmian in difficoltà • TIM avvia il piano di dismissione delle centrali • Promuovere il piano sbagliato
Intelligenze artificiali:
• I prossimi passi per il centro di calcolo Leonardo • I limiti dei benchmark: come si misura la qualità dei modelli linguistici? • Il nuovo stato dell’arte negli LLM open: DBRX di Databricks • xAI presenta Grok-1.5 • La caccia ai talenti • Altri video di Sora, OpenAI testa la clonazione della voce
Cybersecurity:
• L’incredibile backdoor in SSH • Facebook ha spiato gli utenti intercettando il traffico di Snapchat, YouTube, Amazon • I domini più usati per lo spam via email
In real life:
• Il governo non sta rispettando gli obblighi di trasparenza sui dati del PNRR • La nuova piattaforma dei punti di ricarica elettrici, senza open data • Il lavoro straordinario sugli indicatori statistici nel Regno Unito
Regole di Internet
• Come si verifica l’età online?
Una delle più discusse novità introdotte l’autunno scorso dal cosiddetto decreto legge “Caivano” è quella inserita nell’articolo 13-bis, che introduce il divieto per i minori di accedere ai siti web che diffondono pornografia e richiede invece ai siti di verificare la maggiore età degli utenti prima di farli accedere.
L’elefante nella stanza per l’applicazione di questa norma è: come si verifica l’età delle persone online? Quali sono i metodi più affidabili e come si bilancia la protezione della privacy impedendo ai siti web di schedare l’Italia intera? Questa settimana l’AGCOM, cioè l’autorità garante per le comunicazioni, ha avviato un procedimento per definire proprio queste regole, cioè dei requisiti minimi per i sistemi di verifica dell’età online.
Il documento che l’AGCOM ha sottoposto a consultazione pubblica è molto lungo, 51 pagine con diversi allegati e approfondimenti, e presenta prima di tutto i metodi più comunemente usati dai regolatori europei: si menzionano sistemi “banali” e facilmente aggirabili come l’autocertificazione o il vouching (cioè un genitore conferma l’età), ma si discutono anche sistemi come la biometria (es. riconoscimento facciale), l’analisi del comportamento online, l’identificazione digitale (es. SPID o digital wallet) e la verifica dei documenti d’identità.
Alcune di queste tecniche possono essere evidentemente problematiche dal punto di vista della privacy e portare con sé dei bias. Ad esempio si osserva che il sistema di verifica Yoti, molto usato a livello globale, tende a commettere più errori quando il soggetto ha un colore della pelle più scuro o è di sesso femminile. Il sistema al momento preferito dai regolatori europei è l’identificazione digitale, che in Italia può includere anche l’uso della CIE.
L’autorità propone quindi una serie di linee guida, dei requisiti che tutti i sistemi dovrebbero rispettare: si tratta di principi principalmente di buon senso come la proporzionalità, il rispetto della privacy, la sicurezza, la precisione ed efficacia, la facilità d’uso, l’inclusività e non discriminazione, e altri.
L’autorità raccoglierà commenti e osservazioni per un mese, ma restano aperti molti dubbi soprattutto tecnici. Andrà infatti affrontato il problema delle piattaforme video, che difficilmente staranno a guardare (negli USA Pornhub ha chiuso le attività in diversi stati per protesta). Inoltre questo “blocco” sarà probabilmente facile da aggirare usando VPN o strumenti simili.


• Il governo USA fa causa a Apple, ma come finirà?
Il dipartimento di giustizio statunitense ha depositato una causa antitrust contro Apple per l’abuso della sua posizione dominante nel mercato degli smartphone e in generale dei dispositivi elettronici.
Come spiega Mark Gurman di Bloomberg le motivazioni principali sono cinque ma sono in buona parte superate dai fatti: sono questioni che Apple ha già risolto o sta risolvendo e sembra quindi probabile che le accuse saranno ridimensionate.
Più in dettaglio, le motivazioni sono:
— Apple ha limitato lo sviluppo delle cosiddette “super app”, cioè app che contengono tante funzioni come WeChat in Cina. In realtà, WeChat è consentito e a gennaio Apple ha esteso ulteriormente le funzioni che le super app possono avere
— L’App Store non permetteva la pubblicazione di app per servizi di streaming dei videogiochi nel cloud. Da gennaio è però invece possibile
— Apple ha impedito alle app di terze parti di inviare SMS sugli iPhone e iMessage non funziona su Android. L’azienda ha però già annunciato che supporterà lo standard RCS, che migliorerà significativamente l’interoperabilità tra sistemi operativi
— La mancanza di supporto per smartwatch che non siano di Apple, sugli iPhone
— Apple non consente alle app di terze parti di usare la tecnologia Apple Pay per i pagamenti contactless
L’azienda ha ovviamente negato tutte le accuse, ma non può nascondere il fatto che una buona parte delle concessioni che ha fatto nel tempo derivano probabilmente anche dalla costante pressione delle autorità e dal rischio di ripercussioni legali per la sua posizione spesso monopolistica.


• La Spagna ordina il blocco di Telegram, poi cambia idea
Venerdì della settimana scorsa la corte suprema della Spagna ha ordinato il blocco di Telegram in risposta alla segnalazione di un gruppo antipirateria secondo cui Telegram consentirebbe la pubblicazione di materiale protetto da copyright tramite l’app. L’ordine di sospensione è stato però sospeso dopo meno di 48 ore perché la corte ha deciso di approfondire meglio l’impatto che la sospensione avrebbe. Secondo un sondaggio Telegram è usato dal 19% delle persone in Spagna, circa 8 milioni.

Reti e telecomunicazioni
• Piracy Shield: un pasticcio dopo l’altro
Tra siti bloccati per errore, risposte surreali di AGCOM e codici sorgenti pubblicati online, questa settimana la piattaforma antipirateria Piracy Shield ha fatto nuovamente discutere e nel settore il tema è diventato forse il più controverso e commentato degli ultimi anni.
Una delle questioni più controverse è il fatto che il sistema si basa sul blocco permanente di indirizzi IP e che non preveda un sistema di “antidoti” da applicare in caso di errori o variazioni che ci possono essere nel tempo. Secondo quanto riportato da un utente, si è già verificato un primo caso in cui un indirizzo IP precedentemente usato per diffondere contenuti illegali è stato riassegnato dal fornitore cloud (in questo caso OVH) a un altro cliente, che ha poi scoperto che quell’indirizzo era bloccato in Italia. Piracy Shield non sembra prevedere al momento un sistema di sblocco degli indirizzi IP: i soggetti segnalatori, che sono aziende private, possono annullare l’ordine di blocco (il ticket) solo entro 75 secondi oppure segnalare un errore nelle prime 24 ore. Dopodiché il blocco diventa definitivo e l’indirizzo IP va considerato bloccato a vita.
Il rischio di bloccare i siti sbagliati veniva fatto notare dagli esperti da mesi: chiunque abbia un po’ di dimestichezza con il cloud sa che gli indirizzi IP sono spesso risorse effimere, sono riassegnabili con pochi click e c’è quindi da aspettarsi che sia frequente la situazione in cui un indirizzo usato per scopi illegali venga rilasciato non appena l’abusatore si accorge che è stato bloccato.
«Questo meccanismo è stato creato senza considerare come funziona la rete Internet. E non è che se noi scriviamo in una norma che gli asini volano gli asini improvvisante spiccano il volo: c’è un problema di aerodinamica dell’asino»
A complicare ulteriormente le cose c’è il fatto che AGCOM sta rendendo molto complicato presentare dei reclami: l’autorità sostiene che si può segnalare un errore entro cinque giorni dalla “pubblicazione della lista dei blocchi effettuati”, ma la lista dei blocchi effettuati non esiste. La pagina dei provvedimenti di AGCOM contiene infatti solo un riepilogo della quantità di siti bloccati ma non ci sono altri dettagli. Di fatto non esiste quindi un modo ufficiale per verificare i blocchi e presentare reclamo, una situazione paradossale a cui AGCOM non sembra stia dando nessuna attenzione nemmeno dopo mesi di critiche diffuse.
Un mese fa Piracy Shield aveva bloccato per errore un indirizzo IP di Cloudflare, importante servizio di Content Delivery Network (CDN) e di accelerazione di siti web, creando problemi a decine di migliaia di siti. In quel caso Cloudflare aveva consigliato ai propri clienti di inviare un reclamo ad AGCOM, che questa settimana ha risposto spiegando che il blocco era già stato ritirato «in giornata» e quindi non c’era altro da fare, e che comunque il reclamo andava presentato nei primi cinque giorni. In realtà il blocco ha avuto effetti prolungati, addirittura fino a 40 ore per almeno un operatore.

In assenza di trasparenza da parte di AGCOM c’è chi si sta arrangiando: un operatore del Veneto ha realizzato un sito web che permette di verificare se un dominio o un indirizzo IP è stato bloccato da Piracy Shield. È stata proprio questa piattaforma, non ufficialmente autorizzata, a permettere di verificare che l’indirizzo IP di OVH era effettivamente bloccato ingiustamente da Piracy Shield. Se però l’utente non fosse stato presente su Twitter in questi giorni non avrebbe potuto ipotizzare che si trattava di un effetto collaterale del sistema di antipirateria, visto che nella maggior parte dei casi non viene mostrato alcun avviso di blocco.
Tramite questo nuovo portale non ufficiale si è anche scoperto che la piattaforma sta bloccando 15 indirizzi IP di proprietà di Akamai, o più precisamente di Linode, un brand che ha acquisito un anno fa e che offre servizi cloud. Akamai è una storica azienda di Internet (è nata nel 1998) e offre quello che è considerato il servizio CDN più esteso del mondo (per dare un’idea della dimensione del business, il fatturato di Akamai è circa tre volte quello di Cloudflare). Il fatto che indirizzi IP a disposizione di Akamai siano ora bloccati permanentemente sta preoccupando molti: è irrilevante che oggi non siano usati per la CDN o per altri servizi condivisi, perché potrebbero diventarlo in qualsiasi momento e Piracy Shield non ne tiene conto.
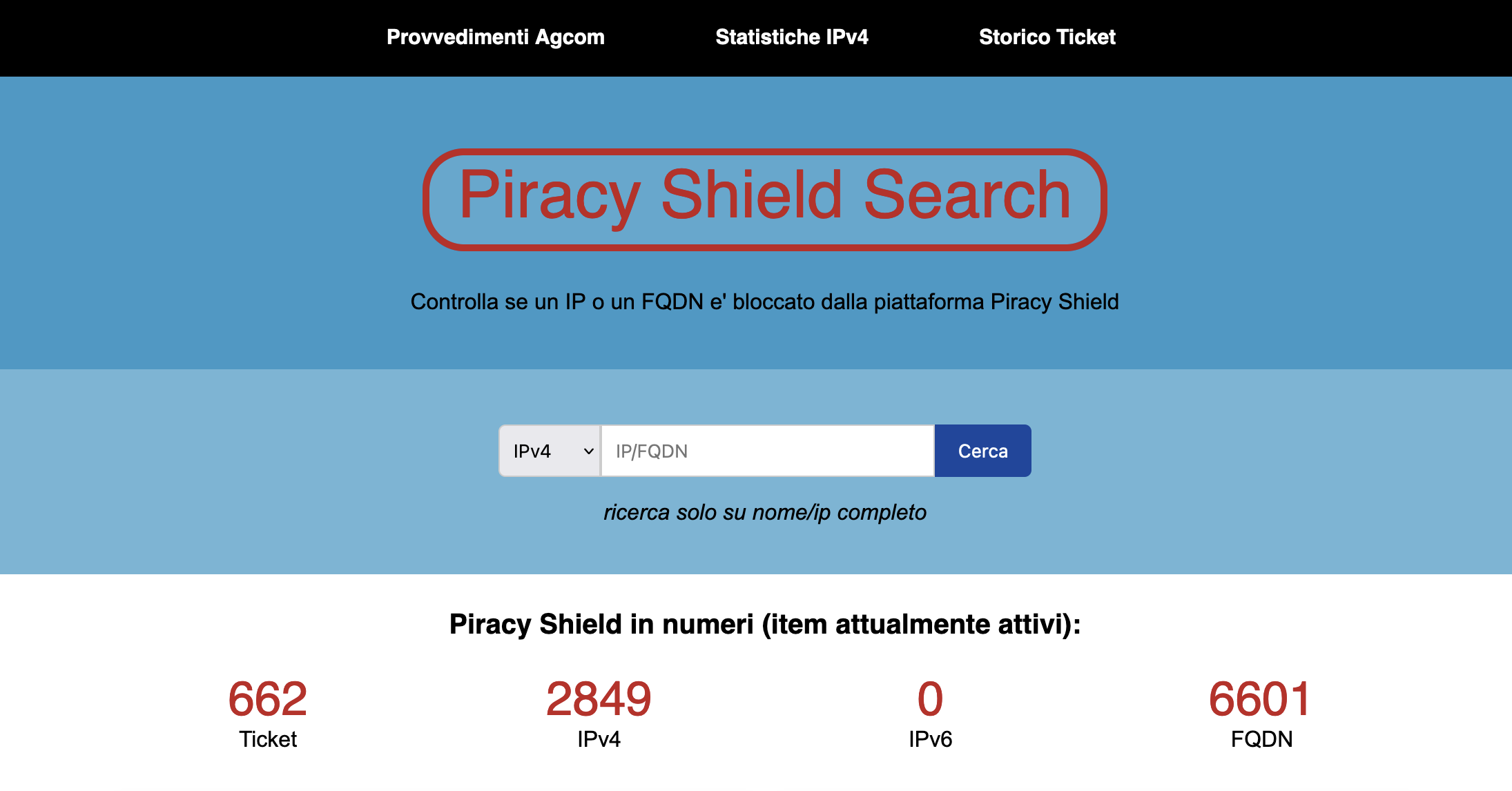
Inoltre, dai dati si ricava che il sistema sta bloccando indirizzi IP al ritmo di circa 1500 al mese: significa 18mila IP all’anno bloccati in modo permanente. È una quantità enorme e a un certo punto potrà iniziare ad avere effetti percepibili sulla disponibilità dei servizi (legali) in Italia.
Pochi giorni fa l’AGCOM ha anche risposto a una richiesta di accesso agli atti di un utente che voleva ottenere qualche dettaglio in più sul blocco di Cloudflare. L’autorità ha scritto che non fornirà nessuna informazione perché i “controinteressati” si sono opposti. Significa cioè che i soggetti segnalatori, che ricordiamo sono privati e includono tra gli altri la Lega Serie A, Serie B, DAZN e Sky, non solo hanno l’enorme potere di poter bloccare qualsiasi risorsa Internet in Italia, ma quando sbagliano non esiste nessuna assunzione di responsabilità e possono anzi rifiutarsi che vengano diffusi dettagli sull’errore che è stato commesso. Se, quindi, un’azienda subisce un danno per effetto di un blocco fatto per errore non ha modo di rivalersi perché non esiste traccia pubblica e l’AGCOM declina ogni richiesta di informazioni.

La ciliegina sulla torta è stata poi la pubblicazione (illegale) su GitHub del codice sorgente di molte componenti di Piracy Shield: non è al momento molto chiaro se si sia trattata di una fuga proveniente dall’interno o di un attacco dall’esterno, ma è in ogni caso preoccupante che le autorità non riescano a mantenere il pieno controllo su un sistema che ha il potere di creare gravi disservizi nazionali. Finora di commenti ufficiali c’è solo quello della Lega Serie A, che ha diffuso un comunicato un po’ sgangherato in cui dopo aver confermato l’«illecita diffusione» ha anche accusato di «tentativi di sabotaggio» i «criminali che gestiscono le IPTV illecite e i loro amici».
Sta di fatto che la pubblicazione del codice sorgente non dovrebbe essere considerata un fatto clamoroso ma qualcosa da incentivare e realizzare ufficialmente nel contesto di un sistema di questa delicatezza. E infatti l’analisi del codice ha permesso di chiarire diversi punti finora oscuri, tra cui il fatto che quella che AGCOM chiama «prova forense» è in realtà un file ZIP. Come fa però notare Stefano Zanero, professore ordinario del Politecnico di Milano esperto in sicurezza informatica, per dimostrare che un indirizzo IP corrisponde univocamente soltanto a un sito web illegale serve qualcosa di più preciso e dettagliato.
«Piccola lezione gratuita […] di Digital Forensics per authority in crisi esistenziale. Se chiami un file zip “prova forense” l’esame non lo passi»
Si ha avuto poi conferma del fatto che il sistema non prevede il concetto di “sblocco” né un audit trail: gli operatori devono estrarre ogni volta la lista completa di ticket e confrontare cosa è stato aggiunto e cosa è stato rimosso, un grosso limite che sta complicando la vita agli operatori.
Cara Italia, sai fare di meglio.
• OVH aprirà un datacenter in Italia
Il servizio cloud francese OVH ha annunciato che aprirà un datacenter in Italia. Si tratta in particolare di una “local zone”, quindi non un datacenter dove saranno offerti tutti i servizi cloud ma solo un sottoinsieme di servizi “edge”. È importante perché OVH è una delle pochissime alternative europee ai grandi cloud hyperscaler statunitensi ed è quindi positivo che diffonda la sua presenza in nuovi paesi europei.

• C’è fibra e fibra: l’italiana Prysmian in difficoltà
La concorrenza asiatica sta mettendo in difficoltà la produzione di fibra ottica di qualità in Europa. Scrive Il Sole 24 Ore che un chilometro di fibra ottica di bassa qualità prodotta in Cina e Asia può costare 2,3 euro al chilometro contro i circa 6,5 euro della fibra “premium”, che in Europa è prodotta principalmente dall’azienda italiana Prysmian negli stabilimenti di Battipaglia, in Campania, e di Douvrin, in Francia.
Nonostante ci sia una forte domanda di fibra ottica, i bandi pubblici in Italia non impongono parametri di qualità e affidabilità sulla fibra e quindi le aziende sono libere di scegliere fibra economica dall’Asia piuttosto che quella più costosa ma di qualità maggiore. Prysmian dice che le commesse sono al minimo e si lavora a un quarto della capacità di produzione. Lo stabilimento italiano potrebbe quindi dover interrompere la produzione, a meno che non si decida come in Francia di inserire dei requisiti di qualità per la realizzazione delle reti in fibra e sostenere così l’industria nazionale.

• TIM avvia il piano di dismissione delle centrali
Dopo lunghissimi ritardi, TIM ha annunciato che a maggio inizierà il piano di dismissione delle centrali spegnendo le prime 35 in quattro regioni. I clienti che non siano già in tecnologie a banda ultralarga come FTTC o FTTH saranno attivati con queste tecnologie senza costi. Le linee faranno quindi capo a un’altra centrale, si presume la più vicina, ma dovrebbe essere un processo in larga parte impercepibile per le persone.
L’obiettivo è ridurre i costi. Le centrali capillari hanno meno senso oggi che tecnologie come l’ADSL sono in via di estinzione. Non significa comunque un “addio al rame”, come si sta leggendo online, visto che la copertura TIM è ancora prevalentemente FTTC e cioè con l’ultimo tratto in rame. Il piano attuale comunque prevede lo spegnimento di circa 1300 centrali in totale, ma è stato un progetto travagliato: si è iniziato a parlarne già nel 2018, quando la previsione era invece di dismetterne quasi 7mila. Quel piano non è però mai stato attuato e le operazioni di fatto iniziano ora.

• Promuovere il piano sbagliato
Il Ministero delle imprese ha avviato una campagna di comunicazione su radio, tv e giornali per divulgare le iniziative del governo su banda ultralarga e 5G. Purtroppo però il ministero sembra un po’ confuso e sta pubblicizzando il piano banda ultralarga approvato dal 2015 dal governo Renzi. Quel piano è stato superato e integrato da un nuovo piano aggiornato, che è invece del 2021. Ci sarebbe anche un nuovo sito che illustra i progetti finanziati dal PNRR ma la campagna non ne fa menzione.
Intelligenze artificiali
• I prossimi passi per il centro di calcolo Leonardo
I modelli di intelligenza artificiale generativa richiedono risorse hardware, in particolare GPU, in grandi quantità. In Italia abbiamo Leonardo, un datacenter di high-performance computing (HPC) a cui le università italiane fanno forte affidamento per i propri lavori di ricerca. Nonostante Leonardo sia il secondo cluster più grande in Europa è già al limite delle sue capacità ed entro giugno sarà fatto un upgrade chiamato Lisa. In parallelo si sta già pensando all’evoluzione futura, il progetto Elisa, che porterà ulteriori ampliamenti: il completamento di questa fase era previsto entro il 2028 ma vista la forte domanda è stato anticipato al 2025/2026.

• I limiti dei benchmark: come si misura la qualità dei modelli linguistici?
Dal lancio di ChatGPT non c’è stato mese senza che spuntassero nuovi modelli linguistici (LLM), e periodicamente sono state pubblicate classifiche sulla qualità dei modelli. Misurare la qualità di sistemi che usano il linguaggio naturale è però molto difficile, perché c’è un certo grado di soggettività nel determinare se una risposta è di buona qualità.
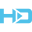
Un benchmark spesso preso come riferimento è la cosiddetta Chatbot Arena della Large Model System Organization. È una classifica basata sul feedback fornito da una grande quantità di persone umane, tramite dei “blind test”. Gli ultimi dati pubblicati pochi giorni fa mostrano per la prima volta un modello superare GPT-4 di OpenAI, finora leader indiscusso: si tratta di Claude 3 Opus, l’LLM di punta di Anthropic rilasciato poche settimane fa.
«The king is dead»
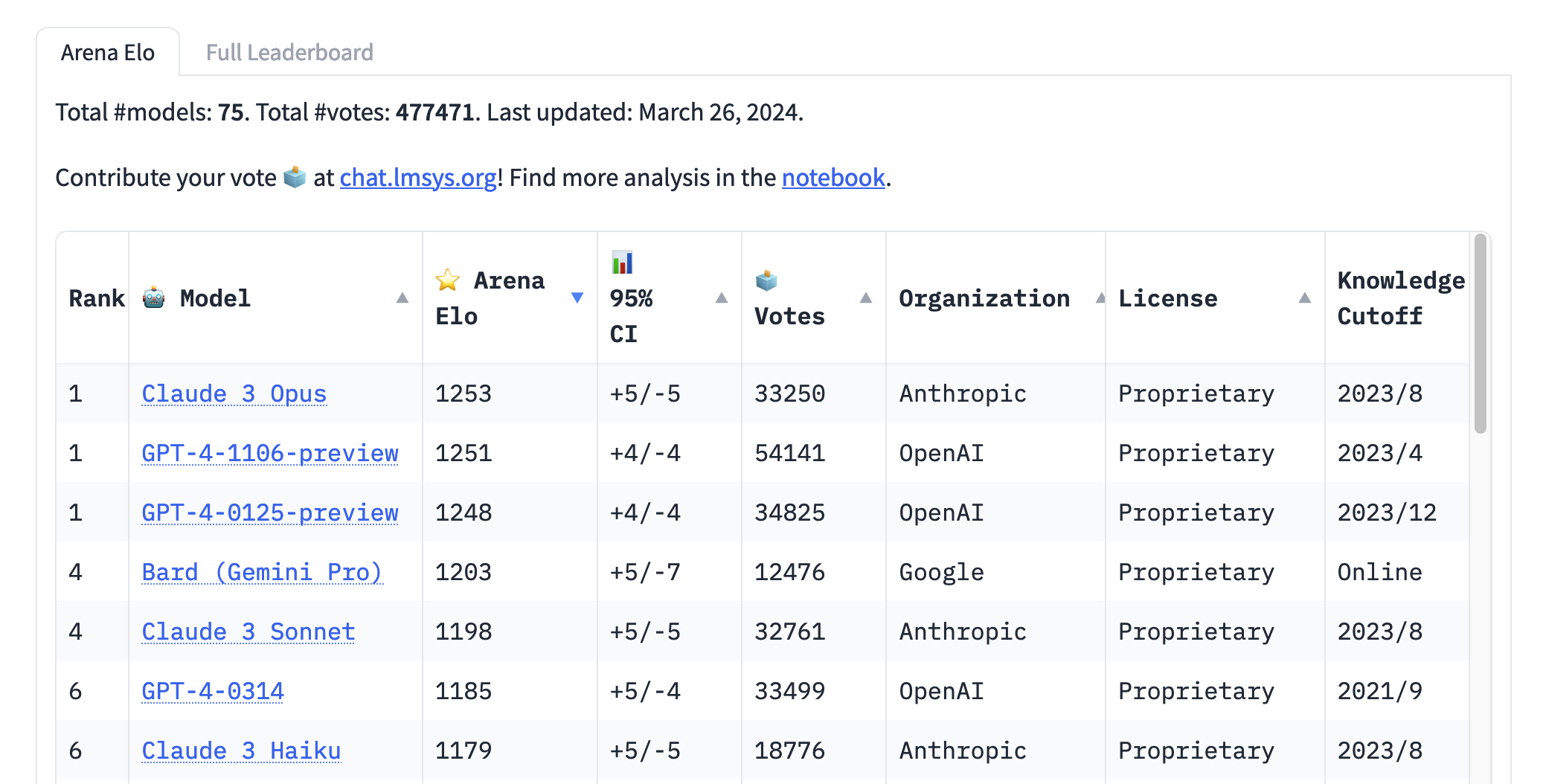
Il problema dei benchmark è che tendono spesso ad essere inquinati: con il tempo gli LLM stessi apprendono i test “a memoria” e quindi i benchmark perdono di valore. Un approccio alternativo per misurare le capacità di ragionamento degli LLM è stato pubblicato questa settimana e consiste nel predire mosse degli scacchi: con questo test GPT-4 resta largamente in testa.

• Il nuovo stato dell’arte negli LLM open: DBRX di Databricks
Databricks ha pubblicato un nuovo modello linguistico open che secondo i benchmark batte tutte le alternative al momento disponibili pubblicamente, inclusi Llama 2 di Meta, Mixtral della francese Mistral e Grok-1 di xAI. Il training è costato 10 milioni di dollari ed è durato diversi mesi. Eseguire il modello richiede 264 GB di RAM, per cui non è esattamente alla portata di tutti.
«Wait, did we beat Elon’s thing?»

• xAI presenta Grok-1.5
L’azienda di intelligenza artificiale di Elon Musk ha annunciato che il suo LLM Grok ha fatto significativi progressi in termini di qualità con la nuova versione chiamata Grok-1.5. Il nuovo modello offre capacità di ragionamento migliorate e una lunghezza del contesto, cioè l’input, di 128mila token con risultati ottimi nel test “ago nel pagliaio”.
La settimana scorsa xAI aveva reso pubblico il modello precedente, Grok-1, che però non aveva sorpreso particolarmente.
• La caccia ai talenti
Le grandi aziende di tecnologia stanno facendo di tutto per riuscire a rubare un esperto in intelligenza artificiale in più. Sono competenze relativamente rare e per questo anche i compensi sono superiori: secondo i dati riportati dal Wall Street Journal il compenso complessivo medio negli USA (comprendente salario, bonus e azioni) per ruoli legati all’AI sfiora i 300mila $ annui, quasi il doppio rispetto agli ingegneri che lavorano in altri campi. Ci sono aziende come OpenAI che ci stanno dando dentro particolarmente con gli stipendi, arrivando anche a un milione di dollari.
Anche a Meta, una delle aziende maggiormente focalizzate sulla ricerca, i compensi per gli ingegneri in AI sono notevoli con una media di 400mila $. Si dice anche che Meta stia facendo offerte di lavoro senza nemmeno intervistare i candidati, con Mark Zuckerberg in persona a contattare le figure che sarebbero più utili per l’azienda.
Non è tutto Stati Uniti però: secondo un recente rapporto, anche la Cina sta investendo molto nel creare talenti nel campo dell’intelligenza artificiale, aumentati dal 10% al 26% in tre anni.

• Altri video di Sora, OpenAI testa la clonazione della voce
OpenAI ha pubblicato nuovi video generati con Sora, il modello che permette di creare brevi video a partire da un testo. Questa volta sono stati realizzati “in collaborazione con artisti, designer, direttori creativi e registi” e in effetti assomigliano più a dei cortometraggi. Se volete dare un’occhiata, li trovate qua, sapendo però che questi video hanno generato nuovamente accuse di “artist-washing”, cioè tentativi di mostrare solo i commenti positivi degli artisti senza considerare che Sora è stato addestrato a partire da opere artistiche senza un compenso per gli artisti. A differenza di OpenAI, Adobe ha ad esempio seguito un altro approccio con il suo prodotto Firefly, assicurandosi di avere il permesso per usare il materiale.

Sempre questa settimana OpenAI ha annunciato che sta testando anche un nuovo sistema di “voice cloning”, cioè un’AI che è in grado di imparare la voce di una persona e poi generare nuovo audio sintetizzato. A stupire questa volta è il fatto che le voci vengono apprese a partire da tracce di esempio molto brevi, anche di 15 secondi, e che l’audio generato può essere anche in altre lingue. Per via della delicatezza di questa tecnologia, al momento è stata condivisa solo con un gruppo ristretto di aziende, circa un centinaio.


Cybersecurity
• L’incredibile backdoor in SSH
È stato scoperto un grave problema di sicurezza in uno strumento di compressione (xz) installato nella maggior parte dei sistemi basati su Linux. Lo strumento riusciva a iniettare del codice nel sistema di autenticazione di SSH di fatto introducendo una backdoor, cioè la possibilità per un estraneo di ottenere accesso da remoto al sistema. (SSH è un protocollo per l’accesso sicuro a computer o server remoti ed è estremamente usato nell’ambito dei sistemi Linux.)
La cosa incredibile è che la backdoor è stata volutamente inserita da uno dei due principali collaboratori del progetto xz, un utente noto come JiaT75 con diversi anni e centinaia di contributi a xz. Non è ancora chiaro se lo sviluppatore possa aver inserito altre vulnerabilità nello strumento, che si può stimare sia usato quotidianamente da milioni di persone e aziende. Non è nemmeno chiaro chi sia realmente il collaboratore e chi ci possa essere dietro.
Fortunatamente ci si è accorti abbastanza in fretta che c’era qualcosa che non andava e la versione di xz vulnerabile sembra sia stata distribuita sui canali stable solo nel caso delle distribuzioni Arch Linux e Kali Linux, che sono relativamente poco diffuse. Per chi usa ad esempio Debian, Ubuntu, altre distribuzioni o anche macOS il problema non dovrebbe essere presente, ma è comunque un forte promemoria che una buona parte della sicurezza informatica si basa sulla fiducia.
• Facebook ha spiato gli utenti intercettando il traffico di Snapchat, YouTube, Amazon
Da dei documenti giudiziari si è scoperto che Facebook ha avuto per diversi anni un progetto per intercettare il traffico degli smartphone verso i server di raccolta di statistiche di Snapchat, YouTube e Amazon. L’obiettivo era raccogliere dati su come gli utenti usavano le app rivali ma la pratica potrebbe violare le leggi sulle intercettazioni.
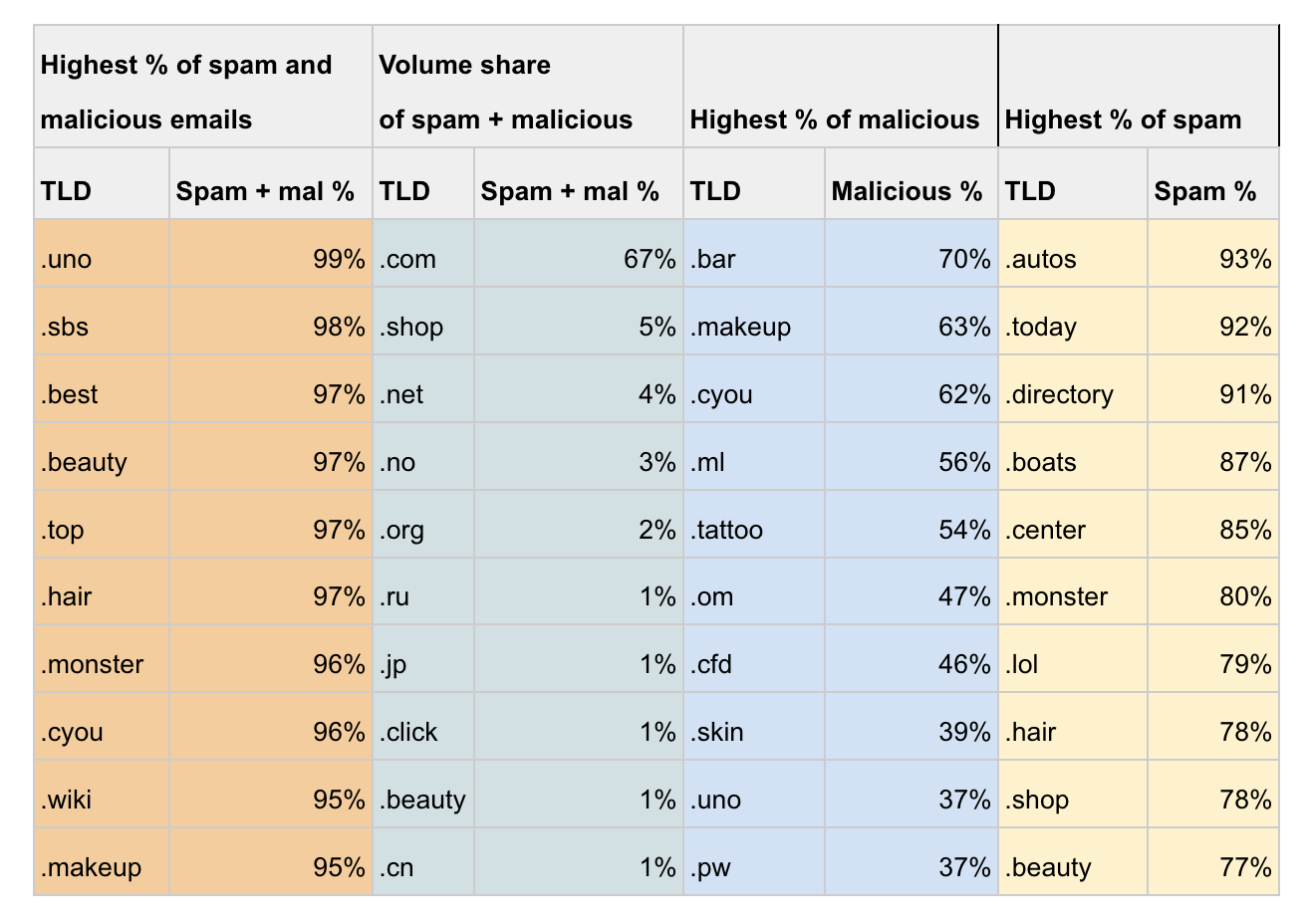
• I domini più usati per lo spam via email
Cloudflare ha pubblicato un’analisi dei domini di primo livello (o TLD, cioè la parte finale dei domini, es. .com) che sono maggiormente usati per l’invio di spam. Ne esce quello che da tempo era una sensazione di molti, cioè che i nuovi domini di primo livello generici come .uno, .top, .best, ecc. sono pesantemente usati per lo spam. Molti TLD sono addirittura usati quasi esclusivamente per inviare spam o email malevoli. È uno dei motivi per cui si tende ad evitare di usare questi domini per email aziendali o comunque che hanno bisogno di una certa affidabilità: il rischio che le email vengano filtrare dai sistemi antispam è maggiore.

In real life
• Il governo non sta rispettando gli obblighi di trasparenza sui dati del PNRR
Dopo la revisione del PNRR di dicembre scorso, il governo si è fatto attendere sulla pubblicazione dei dati aggiornati su progetti, finanziamenti e scadenze. Solo questa settimana sono stati pubblicati dei dati, in formati tipici degli open data (CSV), ma non sono mancate segnalazioni sul fatto che i dati sono pieni di lacune e anche di errori da principianti nella formattazione dei dati. Se non fosse per la dedizione di associazioni come onData questi errori probabilmente non sarebbero stati nemmeno rilevati.
Idealmente questi dati dovrebbero permette di monitorare in dettaglio l’avanzamento dei progetti e di presentarli di conseguenza su portali come OpenPNRR.it, un sito realizzato dall’associazione Openpolis che pubblica i dati del PNRR (in sostituzione del governo, che ha realizzato il portale Italia Domani con però scarsi risultati di trasparenza). È chiaro però che i dati non sono sufficientemente precisi o dettagliati per poter monitorare in modo efficace il progresso dei progetti.
«Sapere quante risorse pubbliche sono destinate a quali progetti, dove e perché è un diritto di cittadini, imprese, amministrazioni locali. Oltre a essere un obbligo di trasparenza che il governo continua a non rispettare.»
• La nuova piattaforma dei punti di ricarica elettrici, senza open data
Il ministero dell’ambiente ha annunciato un nuovo sito, la Piattaforma Unica Nazionale (PUN). È un nome insensato per quella che è in realtà una mappa dei punti di ricarica per veicoli elettrici sul territorio nazionale. È una buona iniziativa, ma da subito il nuovo portale ha fatto discutere per le numerose scelte discutibili: a partire dal nome, il dominio piattaformaunicanazionale.it (anziché .gov.it), il fatto che non funzioni senza www davanti, per arrivare a questioni più serie come l’assenza di open data.
Come capita spesso, ad estrarre i dati ci ha pensato l’associazione onData. Sono bastata poche ore perché i dati venissero usati per creare visualizzazioni grafiche sia da giornali come Il Post che da altri guru delle mappe e dei dati aperti. Potreste pensare che la mappa qua sotto è quella del portale PUN, ma in realtà è stata creata dalla community con «dati strappati» dal portale pubblico. Purtroppo l’ennesimo segnale che la cultura dei dati è in generale scarsamente presente all’interno delle istituzioni pubbliche.
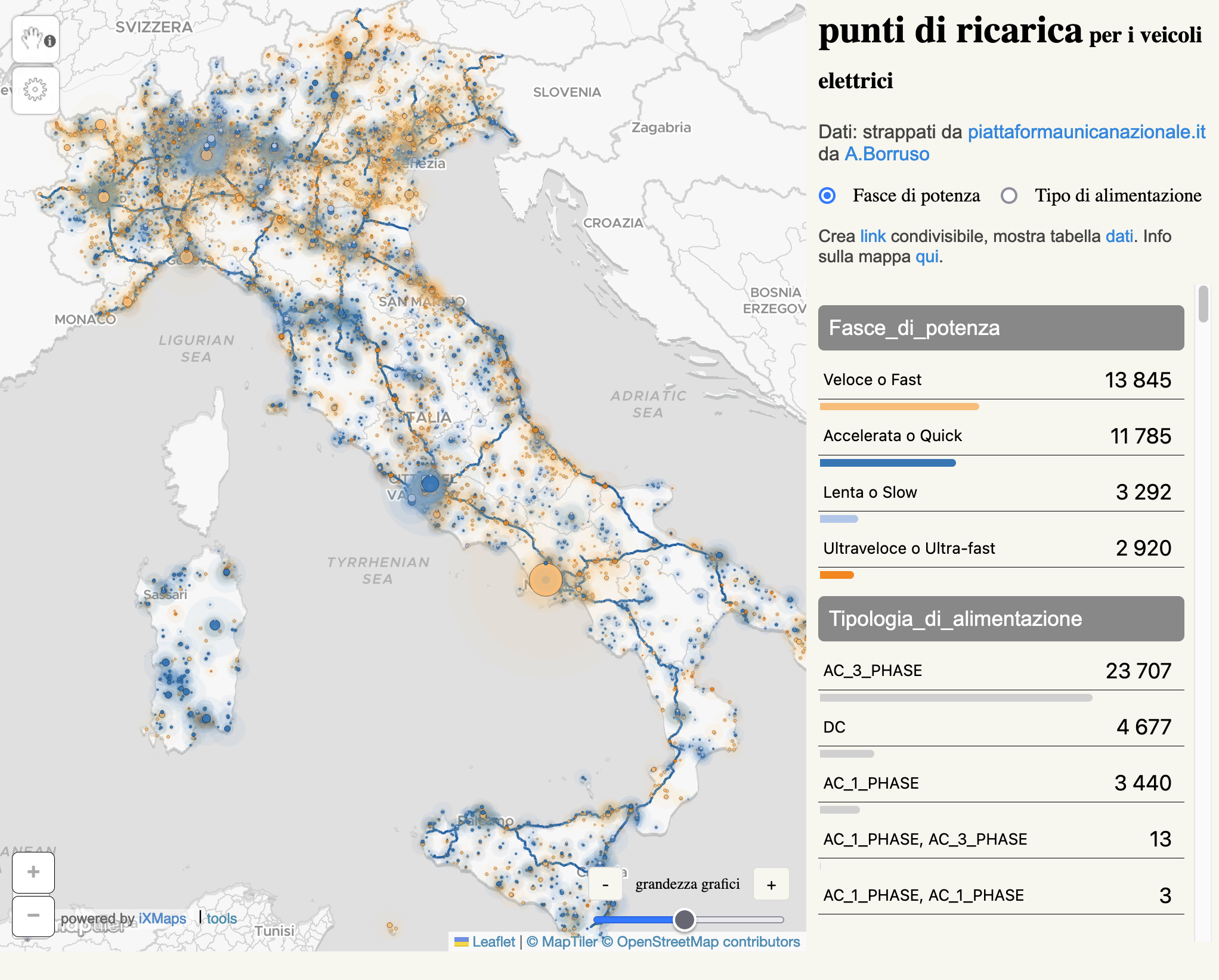

• Il lavoro straordinario sugli indicatori statistici nel Regno Unito
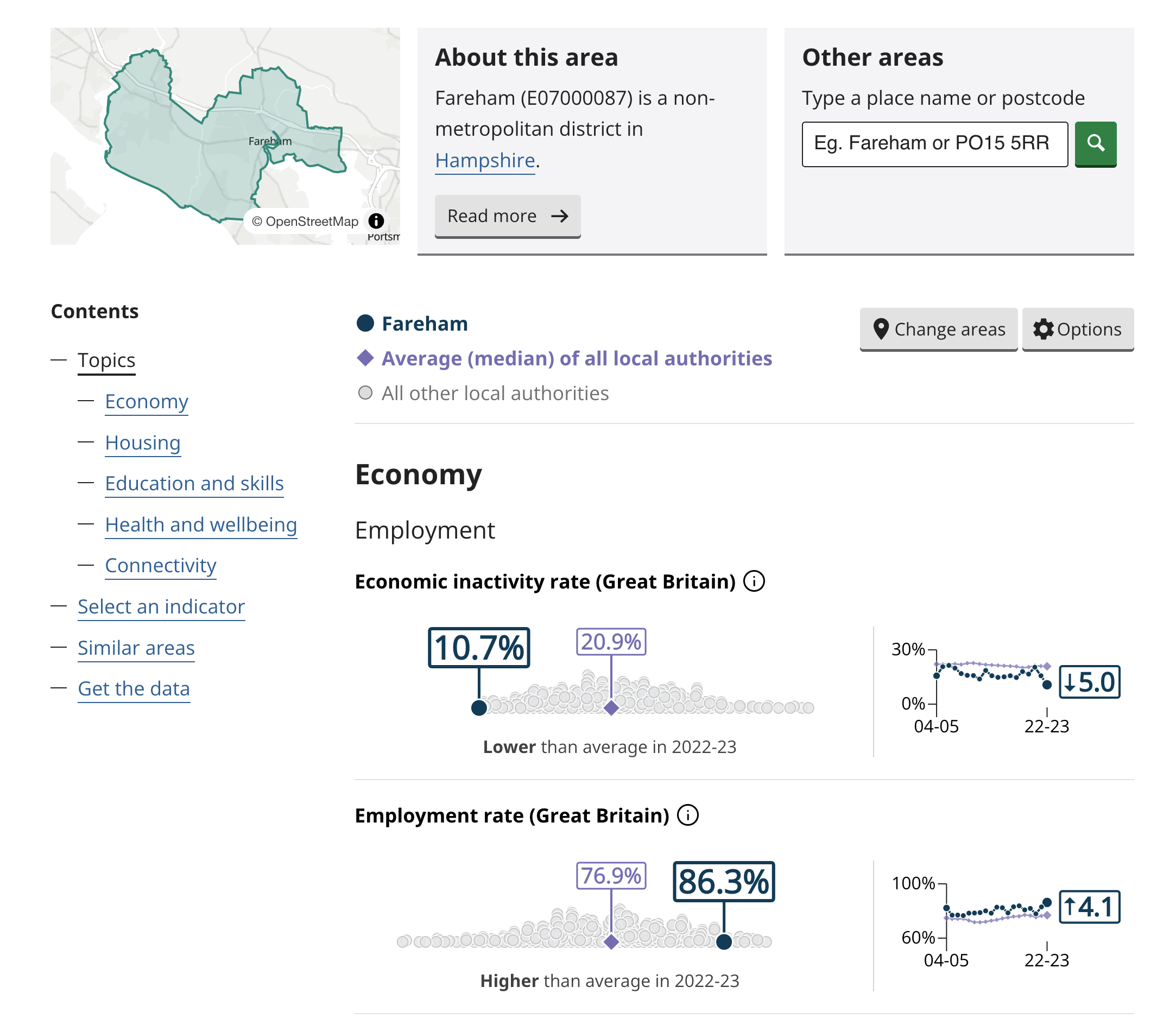
L’Office for National Statistics, l’equivalente dell’ISTAT del Regno Unito, ha lanciato in anteprima sperimentale un nuovo progetto per esplorare i dati statistici a livello locale. Si tratta di 57 indicatori locali che includono ad esempio il reddito, la disoccupazione, la soddisfazione di vita, l’educazione. A livello granulare, anche di singola città, è possibile consultare gli indicatori. Un incredibile lavoro di trasparenza, ovviamente open source, che al momento in Italia non ha equivalenti.
Appunti
</ in ~28 kB >