Le storie della settimana
Questa settimana:
Regole di Internet:
• In breve • Fermare l‘“enshittification” 💩
Intelligenze artificiali:
• In breve • La ricerca AI di Google potrebbe essere a pagamento • A che punto è il “ChatGPT italiano” di Fastweb • La capacità di ragionare dei modelli linguistici: il “prompt engineering” è morto? • Bolla o non bolla • Le pubblicazioni scientifiche scritte con ChatGPT
Reti e telecomunicazioni:
• In breve • Piracy Shield e AGCOM: la realtà supera Kafka • Fastweb è ora un fornitore di energia elettrica
Cybersecurity:
• La backdoor che ha quasi infettato il mondo
Regole di Internet
• In breve
— Google ha accettato di cancellare i dati sugli utenti raccolti mentre navigavano con la “modalità in incognito”, nell’ambito di una class action presentata in California. (Il Post, DDay, The Register)
— Microsoft separerà Microsoft Teams dal resto di Microsoft 365 in tutto il mondo, come già avvenuto in Europa, per prevenire ulteriori indagini di antitrust. (Reuters)
— La Cina bandirà l’uso di tecnologie statunitensi nei computer e server del governo: sono inclusi i chip Intel e AMD ma anche il sistema operativo Microsoft Windows. (Engadget)
• Fermare l‘“enshittification” 💩
Nel novembre 2022 un articolo del Financial Times di Cory Doctorow coniò il termine enshittification (merdificazione) per descrivere la tendenza al degrado di tutte le grandi piattaforme e servizi digitali di Internet. In un articolo di poche settimane fa, tradotto da Internazionale, lo stesso giornalista ha sintetizzato: «È un processo in tre stadi: all’inizio, le piattaforme tecnologiche sono al servizio degli utenti; poi cominciano a maltrattare gli utenti per soddisfare le esigenze dei clienti aziendali; quindi maltrattano i clienti aziendali per tenersi tutto il guadagno. A quel punto c’è un quarto stadio: muoiono».
È il caso ad esempio di Facebook, che ha inizialmente convinto moltissime persone e ha potuto beneficiare dell’effetto rete ma è ora al centro di uno scandalo dopo l’altro. Se n’è riparlato proprio la settimana scorsa quando si è scoperto che Facebook ha spiato gli utenti Snapchat, YouTube e Amazon e venduto a terzi l’accesso ai messaggi privati.
Doctorow si chiede se stiamo entrando nella merdocene, periodo in cui tutti i servizi Internet faranno questa fine, o se possiamo farci qualcosa. Si possono individuare quattro forze che che possono «frenare gli impulsi merdificanti» delle imprese: la concorrenza, la regolamentazione, il “fai da te” (es. la possibilità di bloccare la pubblicità) e i lavoratori.

Nel corso degli anni questi fattori hanno iniziato a venire meno: le autorità antitrust hanno chiuso un occhio per molto tempo rinunciando a tutelare la concorrenza; la regolamentazione si è dimostrata insufficiente e le sanzioni sono spesso state irrilevanti rispetto ai benefici che le grandi aziende traggono dal violare leggi come quella sulla privacy; il “fai da te” è stato ostacolato spingendo gli utenti a usare le app, dove non si può bloccare la pubblicità, e impedendo a tutti i costi che si creassero app alternative; i lavoratori hanno perso il potere negoziale dal momento in cui alcune, poche, big tech hanno iniziato a strapagare i dipendenti e a trasformare i posti di lavoro in dei campus con molti benefit a cui è difficile rinunciare.
«Uno per uno, tutti questi vincoli sono stati erosi e l’impulso merdificante, ormai incontrollato, ci ha proiettati nell’era del merdocene»
Qualcosa sta cambiando? Forse sì. Le autorità antitrust stanno bloccando acquisizioni e fusioni come non si vedeva da molto tempo, mentre l’Unione Europea ha iniziato a imporre nuove regole tramite il Digital Markets Act e il Digital Services Act. Forse anche gli Stati Uniti stanno considerando una legge sulla privacy. Sugli altri aspetti siamo invece più lontani, ma già il fatto che le app di messaggistica saranno obbligate ad aprirsi e a diventare interoperabili è un passo nella direzione del “fai da te”. Infine, anche negli Stati Uniti i lavoratori si stanno crescentemente organizzando in sindacati, storicamente poco presenti negli USA, per potersi così tutelare meglio dalle aziende.


Intelligenze artificiali
• In breve
— Microsoft e OpenAI stanno pianificando un investimento da 100 miliardi di dollari per realizzare un supercomputer di GPU entro il 2028. (Startmag)
— In ChatGPT Plus ora si possono modificare le immagini generate da DALL-E. (Wired)
— Dei ricercatori di Apple hanno realizzato un sistema che è in grado di comprendere la struttura dei contenuti mostrati su una schermata e interpretarne il significato. (VentureBeat)
— AssemblyAI ha sviluppato un nuovo modello di trascrizione dell’audio che sembra essere il nuovo stato dell’arte per inglese, spagnolo, tedesco e francese. (AssemblyAI)
— Più di 200 artisti, tra cui molti famosi, hanno firmato una petizione contro l’uso dell’intelligenza artificiale nella musica. (Il Post)
— Stability AI ha annunciato un nuovo modello per generare musica: Stable Audio 2.0. (Stability AI)
— I modelli linguistici di Mistral AI sono ora disponibili su Amazon Web Services. (AWS)
— Secondo uno studio “solo” il 23% degli americani ha usato ChatGPT almeno una volta. (Pew Research Center)
• La ricerca AI di Google potrebbe essere a pagamento
Secondo un’indiscrezione riportata dal Financial Times Google potrebbe offrire la nuova Search Generative Experience, che è in test da circa un anno, solo agli utenti abbonati a Gemini Advanced, che attualmente in Italia costa 21,99 € al mese. Questi utenti continuerebbero comunque a vedere la pubblicità nei risultati di ricerca.
Sarebbe la prima volta che Google fa pagare gli utenti per delle funzioni aggiuntive nella ricerca. Finora il modello della pubblicità era riuscito a sostenere ampiamente le attività di Google, ma l’AI generativa è molto costosa e già un anno fa Google aveva accennato al fatto che non è al momento sostenibile offrire queste tecnologie ai miliardi di utenti che usano Google.

• A che punto è il “ChatGPT italiano” di Fastweb
Fastweb sta lavorando da qualche mese a quello che viene chiamato “il ChatGPT italiano”, cioè un modello linguistico di grandi dimensioni che sia però addestrato sulla lingua e la cultura italiana (o comunque europea). L’obiettivo è evitare che le AI ereditino i bias di lingua e cultura degli altri modelli, al momento creati quasi esclusivamente negli Stati Uniti.
Da quel che si capisce, ma non è chiarissimo, Fastweb sta costruendo il suo modello linguistico da zero e senza fare quindi semplicemente fine-tuning di modelli esistenti. Per un’impresa del genere servono due cose: tante GPU e tanti talenti umani.
Per quanto riguarda le GPU, Fastweb ha annunciato a dicembre di aver acquistato 31 “supercomputer” NVIDIA DGX H100, cioè dei sistemi che contengono al loro interno 8 GPU NVIDIA H100. Fino a non molto tempo fa H100 era il miglior modello di GPU disponibile per questo tipo di applicazioni. Il totale delle GPU è quindi 248 unità, che secondo il Corriere della Sera renderebbero il datacenter Fastweb «il più potente supercomputer del Paese». Sembra però improbabile, considerando che il cluster Leonardo del Cineca è composto da quasi 14mila GPU A100 (anche se sono un gradino sotto rispetto alle H100).
Per quanto riguarda gli ingegneri esperti in deep learning che dovranno occuparsi del progetto, secondo Wired Fastweb sta lavorando in collaborazione con alcune università italiane. È improbabile in effetti che Fastweb avesse al suo interno esperti in modelli linguistici, dato che non si era mai occupata del tema prima dell’anno scorso. Si stima che questo nuovo modello linguistico sarà reso disponibile entro la fine di quest’anno.


• La capacità di ragionare dei modelli linguistici: il “prompt engineering” è morto?
Dall’arrivo di ChatGPT nel novembre 2022 tutti abbiamo provato almeno una volta a conversare con un modello linguistico provando a fargli fare quello che volevamo. La tecnica di formulare una richiesta in modo che massimizzi la capacità del modello di “comprenderla” e di rispondere correttamente è chiamata prompt engineering. In questo anno e mezzo sono persino nati dei lavori dedicati a questo scopo e delle hackaton nelle università.
Nel frattempo ci sono però stati anche diversi studi e ricerche che hanno mostrato come il metodo migliore per far ragionare un modello linguistico sia in realtà sfruttare il modello linguistico stesso: ad esempio con la tecnica chain of thought, catena di pensieri, si può indurre il modello a ragionare a passaggi, come magari farebbe un umano, e quindi produrre risposte più coerenti e con meno errori rispetto alla domanda secca (zero-shot).

Una tendenza più recente riguarda invece il concetto di agente. La tecnica consiste nello sfruttare il modello come un’entità in grado di ragionare e quindi di completare compiti complessi tramite la preparazione di un piano, la sua valutazione e la messa in pratica, senza un intervento umano al di là degli obiettivi iniziali. Dei test hanno mostrato come le tecniche basate su agenti permettono di usare modelli anche non eccezionali, come GPT-3.5, per aumentare le performance dal 50% del zero-shot al 95% del sistema ciclico ad agente.
Queste presunte e forse ancora precoci capacità di ragionare fanno sperare che i modelli linguistici potranno essere usati per risolvere problemi reali che richiedono un adattamento continuo. È il caso ad esempio dei robot umanoidi, che anziché apprendere i comportamenti nelle varie situazioni direttamente da un umano potranno sfruttare i modelli linguistici come motore di ragionamento. Certo poi sarà forse il caso di pensare di incorporare le leggi di Asimov nei robot…

• Bolla o non bolla
A distanza di più di un anno dall’inizio di questa fase di “hype” per l’AI generativa, nessuno ha ancora ben capito se siamo all’interno di una bolla di alte aspettative che finiranno per essere deluse, come è stato per la dot-com bubble della fine degli anni ‘90. Se da un lato, come scrive The Verge, le startup AI non hanno ancora trovato una via sostenibile per il profitto, dall’altra non sembra che i segnali di una bolla siano al momento comparabili con quelli di 25 anni fa.
Ad esempio, durante la bolla delle dot-com le società più importanti erano fortemente sopravvalutate. In finanzia si usa il cosiddetto P/E ratio, cioè il rapporto tra il prezzo delle azioni e gli utili della società, come misura di quanto il prezzo delle azioni sia sopravvalutato dagli investitori rispetto a quanto la società sta realmente producendo. Se società come Cisco erano arrivate addirittura a P/E di oltre 100, oggi aziende come NVIDIA e Microsoft si aggirano tra i 25 e i 30, sostanzialmente nella media rispetto al mercato. Sarebbe quindi un indice di un ottimismo non così esagerato, almeno dal punto di vista finanziario.


• Le pubblicazioni scientifiche scritte con ChatGPT
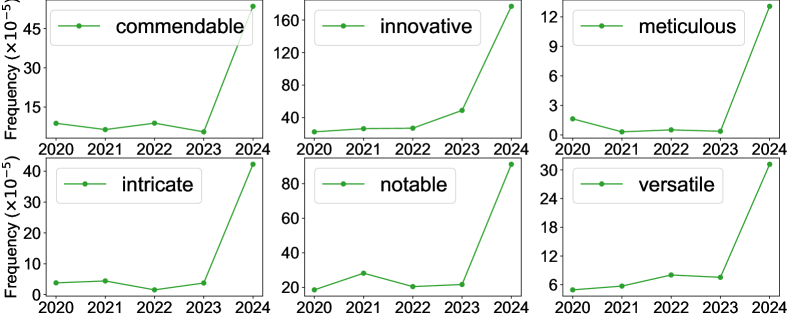
Diverse analisi e studi hanno osservato che negli ultimi mesi c’è stata una curiosa ed improvvisa variazione nello stile di scrittura dei paper scientifici e nelle valutazioni (peer review) dei paper fatte dalla comunità scientifica.
Ad esempio dai dati si nota un picco nell’uso di parole come unwavering, delve, innovative, commendable, intricate. Sembrano termini spesso usati da ChatGPT che sono finiti in materiale scientifico che dovrebbe essere scritto da umani.
Reti e telecomunicazioni
• In breve
— Anche WindTre, dopo TIM e Vodafone, avvia la dismissione del 3G. (MondoMobileWeb)
— L’impatto limitato del terremoto a Taiwan sulle infrastrutture di Internet mostra l’importanza di avere reti resilienti. (Internet Society)
— L’Italia dovrà a pagare a TIM un miliardo di euro per aver riscosso illecitamente un canone di concessione nel 1998. (Il Post)
— Starlink ha inviato degli esposti alle autorità perché TIM non sta comunicando le informazioni necessarie per evitare interferenze sulla banda 28 GHz, usata dal servizio Internet Starlink per collegare le stazioni di terra ai satelliti. (DDay, Startmag, Repubblica €)
• Piracy Shield e AGCOM: la realtà supera Kafka
Non ci sono stati grandi avanzamenti nelle richieste di trasparenza ad AGCOM, l’autorità per le comunicazioni, relative al sistema antipirateria Piracy Shield. Pochi giorni fa l’autorità ha negato un’ulteriore richiesta di accesso agli atti, questa volta di Assoprovider, cioè un’importante associazione che raggruppa centinaia di operatori di telecomunicazioni in Italia.
Non contenta, nel negare la richiesta l’AGCOM è persino arrivata a sanzionare Assoprovider per aver ostacolato l’attività di vigilanza di AGCOM. Assoprovider, che partecipa ai tavoli tecnici di AGCOM, non avrebbe infatti fornito la lista dei soci iscritti all’associazione. Secondo l’autorità fornire la lista era «un requisito imprescindibile ai fini dell’effettivo funzionamento di Piracy Shield», un’affermazione evidentemente assurda. L’AGCOM può sanzionare chi si rifiuta di rispondere alle richieste secondo una legge del 1997 che prevede ancora importi in lire.
Nel frattempo il codice sorgente di Piracy Shield è incredibilmente ancora online su GitHub. Se la scorsa settimana la Lega Serie A aveva confermato che il codice pubblicato si riferiva alla piattaforma, in un’intervista l’amministratore delegato dell’organizzazione ha poi invece negato che sia successo, aggiungendo invece che «gli hacker hanno bucato solo il primo livello di protezione del sito dell’Agcom». Non è chiaro cosa voglia dire, ma se si è trattato effettivamente di un attacco dall’esterno è ancora più grave di quello che si pensava.
«Piracy Shield rende l’Italia un Paese all’avanguardia a livello mondiale»
Poco dopo l’AGCOM ha aggiunto confusione alla confusione con le parole del commissario Massimiliano Capitanio, che ha smentito la versione di Lega Serie A dicendo che «Piracy Shield non è stata hackerata». Nell’evitare di rispondere alle critiche il commissario ha anche affermato che grazie a Piracy Shield «l’Italia è un Paese all’avanguardia a livello globale».
Se però siamo gli unici al mondo ad affidare la censura a dei privati senza nessun controllo da parte delle autorità (probabilmente davvero gli unici: nemmeno in Cina funziona così) forse si potrebbe anche considerare che il motivo non è che siamo più avanti degli altri.



• Fastweb è ora un fornitore di energia elettrica
Fastweb ha lanciato le offerte “luce” con un’innovazione commerciale che finora non si era vista. Le offerte sono infatti come quelle della telefonia: prezzo fisso mensile con inclusa una certa quantità di kWh di energia, da consumare durante l’anno. Se si va oltre il limite si paga una tariffa a consumo. Il prezzo include però tutto, quindi non solo la materia prima anche le altre componenti e l’IVA. Lo svantaggio di questo modello di prezzi è che chi acquista deve avere molto chiaro quali sono i proprio consumi, e le “fasce” previste potrebbero non essere convenienti per tutti: consumando meno della quantità prevista dall’offerta l’energia non consumata è “persa”.
Cybersecurity
• La backdoor che ha quasi infettato il mondo
A distanza di più di una settimana non sono ancora interamente chiari tutti i dettagli di come funziona la backdoor che è stata trovata all’interno di un popolare strumento open source di compressione, xz.
La presenza della backdoor è stata scoperta per una serie di coincidenze da un ingegnere di Microsoft che aveva notato che qualcosa non andava mentre usava SSH, strumento estremamente diffuso per connettersi a server remoti in modo sicuro e oggetto di questo attacco. Se la backdoor non fosse stata scoperta, molti dicono sarebbe stato l’attacco più grande mai fatto a sistemi Linux e avrebbe potuto avere gravissimi impatti anche in sistemi critici.
La cosa che più ha sorpreso è che l‘“impalcatura” che ha permesso di inserire la backdoor all’interno del software è stata costruita e orchestrata lentamente nel corso degli ultimi anni da un soggetto che era difficile sospettare, essendo uno dei principali collaboratori a xz. Questo fatto ha scatenato nuovamente molte discussioni sulla sostenibilità dell’open source: ci sono progetti che sono onnipresenti nei software di tutto il mondo ma che sono poi gestiti nel tempo libero da singole persone volontarie non pagate. L’assenza di supporto da parte delle aziende che usano questi software fa sì che i maintainer di questi progetti siano più vulnerabili a situazioni di questo tipo. Nel caso di xz ha contribuito infatti anche un fattore di social engineering.
In ogni caso, si stanno ancora provando a capire tutti gli aspetti della questione: la backdoor è estremamente sofisticata ed è composta da una serie di passaggi molto complessi da individuare e decifrare anche per una persona esperta. Per chi vuole approfondire, qua e qua si trova una cronologia degli eventi, qua una sintesi in italiano di tutti i fatti, qua e qua una spiegazione molto tecnica ma molto affascinante della parte di codice che innesca l’iniezione della backdoor nel software. Qua su YouTube gli stessi contenuti letti e discussi a voce.

Appunti
- Negli Stati Uniti Amazon toglierà dai suoi negozi fisici la tecnologia con cui si poteva pagare senza usare le casse. (Il Post)
- Sta per arrivare la rete “Trova il mio dispositivo” di Google: permetterà di localizzare dispositivi Android persi come già avviene con i dispositivi Apple. (9to5Google)
- Google migliora la compressione JPEG con Jpegli. (Google)
</ in ~20 kB >