INTELLIGENZA ARTIFICIALE
Meta userà i dati degli utenti per il training dei modelli AI: può farlo?
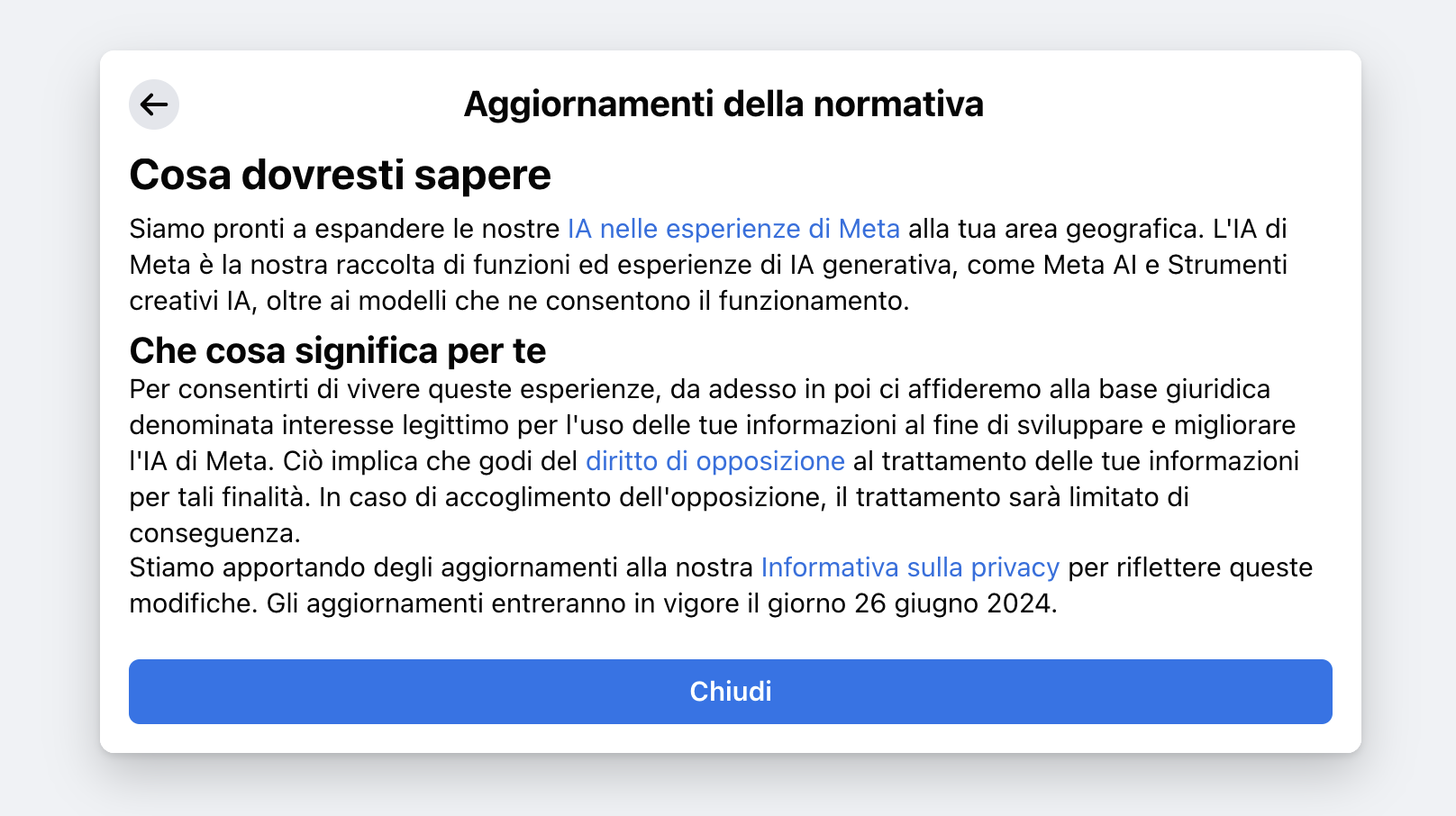
In questi giorni Meta sta comunicando agli utenti di Facebook e Instagram che inizierà ad usare il contenuti dei post e le foto per «migliorare l’intelligenza artificiale su Meta», cioè probabilmente per il training dei modelli di AI generativa.
Per capire se e come Meta può fare un passo del genere ci viene in aiuto un rapporto pubblicato pochi giorni fa dall’EDBP, l’organo europeo che supervisiona i garanti per la privacy degli Stati europei. Il rapporto si concentra su OpenAI ma i concetti si applicano anche a Meta e si riferiscono a tutte le fasi del trattamento dei dati, quindi il preprocessing, il training, la generazione di output dei modelli e il training sugli output stessi.
Dato che parliamo di dati personali (come le foto, ad esempio), il regolamento europeo richiede di mettere nero su bianco in base a quale principio si ha titolo di usare i dati. Ad esempio OpenAI inizialmente usava la “necessità contrattuale”, base poi smontata dal garante italiano. Le alternative sono il consenso, cioè chiedere esplicitamente alle persone se vogliono che i propri dati personali vengano usati per realizzare i modelli, e il legittimo interesse, una base giuridica che richiede che si informino le persone interessate e che si faccia un’attenta valutazione che bilanci gli interessi dell’azienda e i diritti delle persone.
Meta ha scelto il “legittimo interesse” e non dovrà quindi chiedere il consenso ma solo dare la possibilità di contestare l’uso dei dati. Anche OpenAI al momento usa il legittimo interesse ma non è chiaro se può farlo: i dati sono presi da Internet e gli utenti non sono stati informati. Il rapporto dell’EDBP non giunge infatti a una conclusione definitiva: è un grattacapo complesso e non c’è ancora un’interpretazione unica della questione.


Dalla stessa newsletter puoi leggere anche:
- La Lega Serie A ha fatto causa a Cloudflare, una delle più importanti aziende di Internet
- Anche il piano 5G del PNRR è in difficoltà: i comuni negano il 25% delle richieste
- Manca pochissimo allo scorporo della rete TIM e si fanno già le simulazioni
- La Rai inizierà la transizione al DVB-T2 quest'estate
- Quali sono i progetti più avanzati nel campo dei modelli linguistici in Italia
- Le polizie europee e l'FBI hanno smantellato una rete di criminali informatici che gestiva la botnet più grande di sempre
- Neuralink apre una sfida pubblica per risolvere un problema di compressione apparentemente impossibile
- Che aspetto ha il cavo sottomarino danneggiato che collega le isole Svalbard
- Da leggere e da vedere